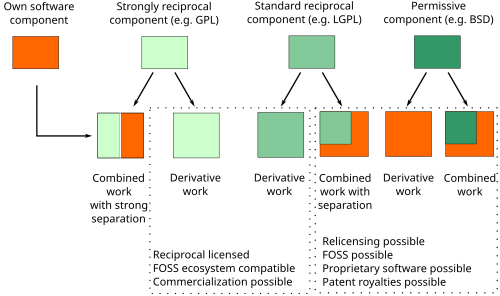Από την απλή ανάκτηση εγγράφων στον έλεγχο της απάντησης πριν φτάσει στον χρήστη
Τα συστήματα RAG δημιουργήθηκαν για να λύσουν ένα πολύ συγκεκριμένο πρόβλημα της γενετικής Τεχνητής Νοημοσύνης: την τάση των μεγάλων γλωσσικών μοντέλων να απαντούν με ευφράδεια ακόμη και όταν δεν γνωρίζουν. Η βασική ιδέα είναι απλή. Αντί το μοντέλο να βασίζεται μόνο στη μνήμη που απέκτησε κατά την εκπαίδευσή του, αναζητά πρώτα σχετικά έγγραφα και στη συνέχεια διατυπώνει απάντηση στηριγμένη σε αυτά. Στην πράξη, όμως, η ανάκτηση του σωστού εγγράφου δεν εγγυάται ότι η τελική απάντηση θα είναι σωστή. Το μοντέλο μπορεί να έχει μπροστά του την ακριβή πηγή και παρ’ όλα αυτά να την παραποιήσει, να αντιστρέψει το νόημά της ή να προσθέσει στοιχεία που δεν υπάρχουν πουθενά.
Αυτό είναι το κρίσιμο σημείο. Η παραισθητική απάντηση σε ένα απλό chatbot μπορεί να αντιμετωπιστεί με επιφυλακτικότητα από τον χρήστη. Σε ένα σύστημα RAG, όμως, η απάντηση εμφανίζεται ως τεκμηριωμένη. Ο χρήστης θεωρεί ότι το σύστημα διάβασε τις πηγές και άρα δικαιούται μεγαλύτερη εμπιστοσύνη. Γι’ αυτό ο περιορισμός των παραισθήσεων δεν μπορεί να σταματά στην καλύτερη αναζήτηση. Πρέπει να υπάρχει ένα επιπλέον στρώμα ελέγχου μετά τη δημιουργία της απάντησης και πριν από την εμφάνισή της.
Οι πέντε συνηθέστερες αστοχίες
Η πρώτη αστοχία είναι η υπερβολική βεβαιότητα χωρίς τεκμηρίωση. Το μοντέλο γράφει «σίγουρα», «είναι σαφές», «όπως αναφέρεται», ενώ η πληροφορία δεν υπάρχει στο ανακτημένο υλικό. Αυτή η μορφή είναι επικίνδυνη επειδή δεν φαίνεται ως αβεβαιότητα αλλά ως αυθεντία. Η δεύτερη είναι η αριθμητική αντίφαση. Το έγγραφο λέει ότι η προθεσμία επιστροφής είναι 14 ημέρες και η απάντηση γράφει 30 ημέρες. Ή η πηγή αναφέρει ότι το πρόγραμμα κοστίζει 120 δολάρια τον χρόνο και η απάντηση το παρουσιάζει ως 10 δολάρια τον μήνα. Η τρίτη είναι η επινόηση προσώπων, οργανισμών ή βιβλιογραφικών αναφορών. Για παράδειγμα, το μοντέλο μπορεί να επικαλεστεί έναν «Dr. James Harrison» ή ένα ανύπαρκτο arXiv paper, ενώ κανένα από αυτά δεν υπάρχει στα σχετικά έγγραφα. Η τέταρτη είναι η αντιστροφή άρνησης. Η πηγή λέει ότι μια υπηρεσία «δεν υποστηρίζει ακύρωση μετά την πληρωμή» και η απάντηση γράφει ότι «υποστηρίζει ακύρωση μετά την πληρωμή». Η πέμπτη είναι η διολίσθηση της απάντησης στον χρόνο. Η ίδια ερώτηση για την τιμή ενός προϊόντος μπορεί να απαντάται επί εβδομάδες ως 49,99 ευρώ και ξαφνικά, μετά από ανανέωση του ευρετηρίου, να επιστρέφει 39,99 ευρώ χωρίς καμία ειδοποίηση.
Έλεγχος πιστότητας, αντίφασης και οντοτήτων
Ένα πρακτικό σύστημα προστασίας πρέπει να εξετάζει την απάντηση με απλούς αλλά αυστηρούς κανόνες. Πρώτα, μετρά την πιστότητα. Χωρίζει την απάντηση σε προτάσεις που περιέχουν πραγματολογικούς ισχυρισμούς και εξετάζει αν οι βασικές λέξεις κάθε ισχυρισμού υπάρχουν στο ανακτημένο υλικό. Αν πολλές προτάσεις δεν μπορούν να συνδεθούν με την πηγή, η απάντηση δεν πρέπει να προωθείται ως αξιόπιστη.
Έπειτα, ελέγχει αριθμούς και χρονικές εκφράσεις. Αν το πλαίσιο λέει «14 ημέρες» και η απάντηση γράφει «30 ημέρες», το σύστημα δεν πρέπει να το αντιμετωπίσει ως μικρή παραλλαγή. Είναι αντίφαση. Το ίδιο ισχύει για τιμές, ποσοστά, ημερομηνίες, εκπτώσεις, όρια χρήσης και περιόδους χρέωσης. Παράλληλα, πρέπει να ελέγχει τις οντότητες. Ονόματα ανθρώπων, εταιρειών, ερευνητικών ιδρυμάτων και παραπομπών πρέπει να εμφανίζονται σε τουλάχιστον ένα ανακτημένο τεκμήριο. Αν δεν εμφανίζονται, η σχετική πρόταση πρέπει να αφαιρεθεί ή να ξαναγραφτεί.
Διόρθωση πριν από την παράδοση
Ο έλεγχος από μόνος του δεν αρκεί. Ένα ώριμο σύστημα πρέπει να αποφασίζει τι θα κάνει με την προβληματική απάντηση. Υπάρχουν τρεις πρακτικές στρατηγικές. Η πρώτη είναι η στοχευμένη διόρθωση αντίφασης. Αν η απάντηση λέει «10 δολάρια τον μήνα» και η πηγή λέει «120 δολάρια τον χρόνο, με ετήσια χρέωση», το σύστημα μπορεί να αντικαταστήσει όχι μόνο τον αριθμό αλλά και όλη τη διατύπωση της περιόδου χρέωσης. Έτσι η πρόταση γίνεται «120 δολάρια τον χρόνο, με ετήσια χρέωση» και δεν μένει πίσω ένα γλωσσικό υπόλειμμα που παραπλανά.
Η δεύτερη στρατηγική είναι η αφαίρεση μη επαληθεύσιμων οντοτήτων. Αν μια απάντηση αναφέρει ερευνητές ή άρθρα που δεν υπάρχουν στις πηγές, οι σχετικές προτάσεις μπορούν να αφαιρεθούν και να προστεθεί σύντομη σημείωση ότι συγκεκριμένα ονόματα ή αναφορές δεν επαληθεύτηκαν. Η τρίτη στρατηγική είναι η ανασύνθεση από την πηγή. Όταν η πιστότητα είναι πολύ χαμηλή, είναι προτιμότερο να ξαναχτιστεί η απάντηση από τις πιο σχετικές προτάσεις των ανακτημένων εγγράφων. Σε περιπτώσεις υψηλού κινδύνου, όπως νομικές, ιατρικές ή διοικητικές υπηρεσίες, η ασφαλής άρνηση είναι προτιμότερη από μια καλοδιατυπωμένη ανακρίβεια.
Τι σημαίνει αυτό για ανοιχτά και αξιόπιστα συστήματα
Ο περιορισμός των παραισθήσεων δεν είναι μόνο τεχνικό θέμα. Είναι ζήτημα λογοδοσίας. Κάθε διόρθωση πρέπει να καταγράφεται. Κάθε αποδεκτή, διορθωμένη ή απορριφθείσα απάντηση πρέπει να αφήνει ίχνος. Οι διαχειριστές πρέπει να βλέπουν αν ένα μοντέλο διορθώνεται συνεχώς στο ίδιο πεδίο, αν ένα ευρετήριο παράγει αστάθεια ή αν μια πηγή δημιουργεί συστηματικές αντιφάσεις. Η λογική είναι απλή: retrieve, generate, inspect, score, heal, deliver. Ανακτώ, παράγω, ελέγχω, βαθμολογώ, διορθώνω και μόνο τότε παραδίδω.
Για την ελληνική γλώσσα και για εφαρμογές δημόσιου ενδιαφέροντος, αυτή η προσέγγιση έχει ιδιαίτερη σημασία. Χρειαζόμαστε RAG συστήματα με ανοιχτά δεδομένα, τεκμηριωμένα σώματα κειμένων, ανοιχτό κώδικα, επαναλήψιμες δοκιμές και ανθρώπινη εποπτεία. Η αξιοπιστία δεν θα προκύψει επειδή ένα μοντέλο είναι μεγάλο. Θα προκύψει επειδή κάθε απάντηση μπορεί να ελεγχθεί, να εξηγηθεί και, όταν χρειάζεται, να διορθωθεί πριν προκαλέσει ζημιά.
Από την απλή ανάκτηση εγγράφων στον έλεγχο της απάντησης πριν φτάσει στον χρήστη
Τα συστήματα RAG δημιουργήθηκαν για να λύσουν ένα πολύ συγκεκριμένο πρόβλημα της γενετικής Τεχνητής Νοημοσύνης: την τάση των μεγάλων γλωσσικών μοντέλων να απαντούν με ευφράδεια ακόμη και όταν δεν γνωρίζουν. Η βασική ιδέα είναι απλή. Αντί το μοντέλο να βασίζεται μόνο στη μνήμη που απέκτησε κατά την εκπαίδευσή του, αναζητά πρώτα σχετικά έγγραφα και στη συνέχεια διατυπώνει απάντηση στηριγμένη σε αυτά. Στην πράξη, όμως, η ανάκτηση του σωστού εγγράφου δεν εγγυάται ότι η τελική απάντηση θα είναι σωστή. Το μοντέλο μπορεί να έχει μπροστά του την ακριβή πηγή και παρ’ όλα αυτά να την παραποιήσει, να αντιστρέψει το νόημά της ή να προσθέσει στοιχεία που δεν υπάρχουν πουθενά.
Αυτό είναι το κρίσιμο σημείο. Η παραισθητική απάντηση σε ένα απλό chatbot μπορεί να αντιμετωπιστεί με επιφυλακτικότητα από τον χρήστη. Σε ένα σύστημα RAG, όμως, η απάντηση εμφανίζεται ως τεκμηριωμένη. Ο χρήστης θεωρεί ότι το σύστημα διάβασε τις πηγές και άρα δικαιούται μεγαλύτερη εμπιστοσύνη. Γι’ αυτό ο περιορισμός των παραισθήσεων δεν μπορεί να σταματά στην καλύτερη αναζήτηση. Πρέπει να υπάρχει ένα επιπλέον στρώμα ελέγχου μετά τη δημιουργία της απάντησης και πριν από την εμφάνισή της.
Οι πέντε συνηθέστερες αστοχίες
Η πρώτη αστοχία είναι η υπερβολική βεβαιότητα χωρίς τεκμηρίωση. Το μοντέλο γράφει «σίγουρα», «είναι σαφές», «όπως αναφέρεται», ενώ η πληροφορία δεν υπάρχει στο ανακτημένο υλικό. Αυτή η μορφή είναι επικίνδυνη επειδή δεν φαίνεται ως αβεβαιότητα αλλά ως αυθεντία. Η δεύτερη είναι η αριθμητική αντίφαση. Το έγγραφο λέει ότι η προθεσμία επιστροφής είναι 14 ημέρες και η απάντηση γράφει 30 ημέρες. Ή η πηγή αναφέρει ότι το πρόγραμμα κοστίζει 120 δολάρια τον χρόνο και η απάντηση το παρουσιάζει ως 10 δολάρια τον μήνα. Η τρίτη είναι η επινόηση προσώπων, οργανισμών ή βιβλιογραφικών αναφορών. Για παράδειγμα, το μοντέλο μπορεί να επικαλεστεί έναν «Dr. James Harrison» ή ένα ανύπαρκτο arXiv paper, ενώ κανένα από αυτά δεν υπάρχει στα σχετικά έγγραφα. Η τέταρτη είναι η αντιστροφή άρνησης. Η πηγή λέει ότι μια υπηρεσία «δεν υποστηρίζει ακύρωση μετά την πληρωμή» και η απάντηση γράφει ότι «υποστηρίζει ακύρωση μετά την πληρωμή». Η πέμπτη είναι η διολίσθηση της απάντησης στον χρόνο. Η ίδια ερώτηση για την τιμή ενός προϊόντος μπορεί να απαντάται επί εβδομάδες ως 49,99 ευρώ και ξαφνικά, μετά από ανανέωση του ευρετηρίου, να επιστρέφει 39,99 ευρώ χωρίς καμία ειδοποίηση.
Έλεγχος πιστότητας, αντίφασης και οντοτήτων
Ένα πρακτικό σύστημα προστασίας πρέπει να εξετάζει την απάντηση με απλούς αλλά αυστηρούς κανόνες. Πρώτα, μετρά την πιστότητα. Χωρίζει την απάντηση σε προτάσεις που περιέχουν πραγματολογικούς ισχυρισμούς και εξετάζει αν οι βασικές λέξεις κάθε ισχυρισμού υπάρχουν στο ανακτημένο υλικό. Αν πολλές προτάσεις δεν μπορούν να συνδεθούν με την πηγή, η απάντηση δεν πρέπει να προωθείται ως αξιόπιστη.
Έπειτα, ελέγχει αριθμούς και χρονικές εκφράσεις. Αν το πλαίσιο λέει «14 ημέρες» και η απάντηση γράφει «30 ημέρες», το σύστημα δεν πρέπει να το αντιμετωπίσει ως μικρή παραλλαγή. Είναι αντίφαση. Το ίδιο ισχύει για τιμές, ποσοστά, ημερομηνίες, εκπτώσεις, όρια χρήσης και περιόδους χρέωσης. Παράλληλα, πρέπει να ελέγχει τις οντότητες. Ονόματα ανθρώπων, εταιρειών, ερευνητικών ιδρυμάτων και παραπομπών πρέπει να εμφανίζονται σε τουλάχιστον ένα ανακτημένο τεκμήριο. Αν δεν εμφανίζονται, η σχετική πρόταση πρέπει να αφαιρεθεί ή να ξαναγραφτεί.
Διόρθωση πριν από την παράδοση
Ο έλεγχος από μόνος του δεν αρκεί. Ένα ώριμο σύστημα πρέπει να αποφασίζει τι θα κάνει με την προβληματική απάντηση. Υπάρχουν τρεις πρακτικές στρατηγικές. Η πρώτη είναι η στοχευμένη διόρθωση αντίφασης. Αν η απάντηση λέει «10 δολάρια τον μήνα» και η πηγή λέει «120 δολάρια τον χρόνο, με ετήσια χρέωση», το σύστημα μπορεί να αντικαταστήσει όχι μόνο τον αριθμό αλλά και όλη τη διατύπωση της περιόδου χρέωσης. Έτσι η πρόταση γίνεται «120 δολάρια τον χρόνο, με ετήσια χρέωση» και δεν μένει πίσω ένα γλωσσικό υπόλειμμα που παραπλανά.
Η δεύτερη στρατηγική είναι η αφαίρεση μη επαληθεύσιμων οντοτήτων. Αν μια απάντηση αναφέρει ερευνητές ή άρθρα που δεν υπάρχουν στις πηγές, οι σχετικές προτάσεις μπορούν να αφαιρεθούν και να προστεθεί σύντομη σημείωση ότι συγκεκριμένα ονόματα ή αναφορές δεν επαληθεύτηκαν. Η τρίτη στρατηγική είναι η ανασύνθεση από την πηγή. Όταν η πιστότητα είναι πολύ χαμηλή, είναι προτιμότερο να ξαναχτιστεί η απάντηση από τις πιο σχετικές προτάσεις των ανακτημένων εγγράφων. Σε περιπτώσεις υψηλού κινδύνου, όπως νομικές, ιατρικές ή διοικητικές υπηρεσίες, η ασφαλής άρνηση είναι προτιμότερη από μια καλοδιατυπωμένη ανακρίβεια.
Τι σημαίνει αυτό για ανοιχτά και αξιόπιστα συστήματα
Ο περιορισμός των παραισθήσεων δεν είναι μόνο τεχνικό θέμα. Είναι ζήτημα λογοδοσίας. Κάθε διόρθωση πρέπει να καταγράφεται. Κάθε αποδεκτή, διορθωμένη ή απορριφθείσα απάντηση πρέπει να αφήνει ίχνος. Οι διαχειριστές πρέπει να βλέπουν αν ένα μοντέλο διορθώνεται συνεχώς στο ίδιο πεδίο, αν ένα ευρετήριο παράγει αστάθεια ή αν μια πηγή δημιουργεί συστηματικές αντιφάσεις. Η λογική είναι απλή: retrieve, generate, inspect, score, heal, deliver. Ανακτώ, παράγω, ελέγχω, βαθμολογώ, διορθώνω και μόνο τότε παραδίδω.
Για την ελληνική γλώσσα και για εφαρμογές δημόσιου ενδιαφέροντος, αυτή η προσέγγιση έχει ιδιαίτερη σημασία. Χρειαζόμαστε RAG συστήματα με ανοιχτά δεδομένα, τεκμηριωμένα σώματα κειμένων, ανοιχτό κώδικα, επαναλήψιμες δοκιμές και ανθρώπινη εποπτεία. Η αξιοπιστία δεν θα προκύψει επειδή ένα μοντέλο είναι μεγάλο. Θα προκύψει επειδή κάθε απάντηση μπορεί να ελεγχθεί, να εξηγηθεί και, όταν χρειάζεται, να διορθωθεί πριν προκαλέσει ζημιά.
Πηγές άρθρου:
Lewis et al., Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks: Η εργασία που εισήγαγε το RAG ως συνδυασμό παραμετρικής μνήμης γλωσσικού μοντέλου και μη παραμετρικής μνήμης μέσω ανακτημένων τεκμηρίων: https://arxiv.org/abs/2005.11401,
Honovich et al., TRUE: Re-evaluating Factual Consistency Evaluation: Χρήσιμη εργασία για την αξιολόγηση της πραγματολογικής συνέπειας παραγόμενων κειμένων και για το γιατί η απλή ευφράδεια δεν αρκεί ως ένδειξη αξιοπιστίας: https://arxiv.org/abs/2204.04991,
Min et al., FActScore: Fine-grained Atomic Evaluation of Factual Precision in Long Form Text Generation: Συμβολή στην αξιολόγηση παραγόμενων απαντήσεων μέσω διάσπασης του κειμένου σε επιμέρους πραγματολογικούς ισχυρισμούς: https://arxiv.org/abs/2305.14251,
Es et al., RAGAS: Automated Evaluation of Retrieval Augmented Generation: Πλαίσιο αξιολόγησης RAG συστημάτων που εξετάζει την ποιότητα ανάκτησης, την πιστότητα της απάντησης και τη συνολική ποιότητα παραγωγής χωρίς να απαιτεί πάντα ανθρώπινη παρέμβαση: https://arxiv.org/abs/2309.15217,
Emmimal, hallucination-detector: Ανοιχτό αποθετήριο με πρακτική υλοποίηση ελέγχου, βαθμολόγησης, διόρθωσης και δρομολόγησης απαντήσεων RAG με δοκιμές για συχνές μορφές παραισθήσεων: https://github.com/Emmimal/hallucination-detector/.
Το Greeks in AI 2026 ανακοίνωσε επίσημα το Call for Papers για το ετήσιο συμπόσιο που θα πραγματοποιηθεί στις 15–17 Ιουλίου 2026 στο Ίδρυμα Ευγενίδου στην Αθήνα, συγκεντρώνοντας ερευνητές, ακαδημαϊκούς και επαγγελματίες της Τεχνητής Νοημοσύνης από την Ελλάδα και το εξωτερικό.
Η διοργάνωση καλεί φοιτητές, υποψήφιους διδάκτορες, μεταδιδάκτορες και νέους ερευνητές να υποβάλουν την πρόσφατη ερευνητική τους δουλειά και να παρουσιάσουν τα αποτελέσματά τους σε ένα διεθνές κοινό με επίκεντρο την AI κοινότητα ελληνικής καταγωγής.
Υποβολές εργασιών έως 15 Μαΐου 2026
Η καταληκτική ημερομηνία υποβολής είναι η 15η Μαΐου 2026, ενώ οι εργασίες θα πρέπει να κατατεθούν μέσω της πλατφόρμας OpenReview.
Οι υποβολές μπορούν να αφορούν papers που έχουν υποβληθεί ή γίνει αποδεκτά μέσα στον τελευταίο χρόνο, καλύπτοντας ένα ευρύ φάσμα θεμάτων στην Τεχνητή Νοημοσύνη και τη Μηχανική Μάθηση.
Οι αποδεκτές εργασίες θα παρουσιαστούν είτε ως:
posters,
spotlight talks,
είτε ως σύντομες 6λεπτες oral presentations κατά τη διάρκεια του συμποσίου.
Ενδεικτικά θέματα ενδιαφέροντος
Μεταξύ άλλων, το Greeks in AI 2026 δέχεται εργασίες στις εξής περιοχές:
Το Coordinate me επιστρέφει για τρίτη χρονιά ως διεθνής διαγωνισμός στο Wikidata, με στόχο την ενίσχυση και εμπλουτισμό δεδομένων που περιλαμβάνουν γεωγραφικές πληροφορίες – από μικρούς οικισμούς και φαρμακεία έως δημόσια τέχνη και φυσικά μνημεία.
Ο διαγωνισμός επικεντρώνεται στη δημιουργία και βελτίωση στοιχείων στο Wikidata που σχετίζονται με συγκεκριμένες χώρες-στόχους, ενισχύοντας έτσι την ποιότητα και την πληρότητα των ανοιχτών γεωδεδομένων.
Το Coordinate me 2026 θα πραγματοποιηθεί από τις 1 έως τις 31 Μαΐου 2026. Κατά τη διάρκειά του, συντάκτες από όλο τον κόσμο θα έχουν τη δυνατότητα να συμμετάσχουν, συμβάλλοντας ενεργά στην ενίσχυση της γνώσης που διατίθεται ελεύθερα μέσω του Wikidata.
Για τη συμμετοχή τους, οι ενδιαφερόμενοι μπορούν να ακολουθήσουν τις αναλυτικές οδηγίες που είναι διαθέσιμες στη σχετική σελίδα του εγχειρήματος.
Συνολικά, θα απονεμηθούν βραβεία αξίας 4.850 ευρώ σε διακριθέντες συμμετέχοντες, ως αναγνώριση της συνεισφοράς τους.
Ο διαγωνισμός υποστηρίζεται από το Wikimedia Community User Group Greece.
Η Ευρωπαϊκή Ένωση εισέρχεται σε μια κρίσιμη περίοδο για τη ρύθμιση του ψηφιακού χώρου. Μετά την υιοθέτηση σημαντικών νομοθεσιών όπως ο Νόμος για τις Ψηφιακές Υπηρεσίες (DSA), ο Νόμος για τις Ψηφιακές Αγορές (DMA) και ο Κανονισμός για την Τεχνητή Νοημοσύνη (AI Act), το ενδιαφέρον στρέφεται πλέον στην εφαρμογή τους και στη διασφάλιση ότι οι νέοι κανόνες θα προστατεύουν πραγματικά τα δικαιώματα των πολιτών.
Στο πλαίσιο αυτό, η Ευρωπαϊκή Επιτροπή προωθεί τον νέο Νόμο Ψηφιακής Δικαιοσύνης (Digital Fairness Act – DFA), με στόχο να αντιμετωπίσει φαινόμενα όπως οι παραπλανητικές πρακτικές σχεδιασμού (“dark patterns”), η καταχρηστική εξατομίκευση περιεχομένου και οι αθέμιτες πρακτικές των ψηφιακών πλατφορμών. Σύμφωνα με τις Οργανώσεις Ψηφιακών Δικαιωμάτων, ο νέος νόμος μπορεί να αποτελέσει σημαντικό βήμα υπέρ των χρηστών — αρκεί να επικεντρωθεί στις πραγματικές αιτίες των προβλημάτων και όχι σε επιφανειακές λύσεις.
Η ανάγκη για προστασία της ιδιωτικότητας
Οι Οργανώσεις Ψηφιακών Δικαιωμάτων τονίζουν ότι η ψηφιακή αδικία βασίζεται κυρίως στη μαζική συλλογή και εκμετάλλευση προσωπικών δεδομένων. Η συνεχής παρακολούθηση των χρηστών και η δημιουργία προφίλ συμπεριφοράς αποτελούν τη βάση πολλών επιβλαβών πρακτικών, από τις χειραγωγικές διαφημίσεις μέχρι τις αδιαφανείς προτάσεις περιεχομένου.
Για τον λόγο αυτό, προτείνεται ο νέος νόμος να περιορίσει τα επιχειρηματικά μοντέλα που βασίζονται στην παρακολούθηση. Οι χρήστες δεν θα πρέπει να αναγκάζονται είτε να παραχωρούν τα προσωπικά τους δεδομένα είτε να πληρώνουν επιπλέον χρήματα για να προστατεύσουν την ιδιωτικότητά τους. Παράλληλα, οι οργανώσεις ζητούν την αναγνώριση αυτόματων ρυθμίσεων απορρήτου από browsers και λειτουργικά συστήματα, ώστε οι πολίτες να μπορούν πιο εύκολα να απορρίπτουν την παρακολούθηση.
Ιδιαίτερη έμφαση δίνεται και στην προστασία των παιδιών. Αντί για υποχρεωτικά συστήματα επαλήθευσης ηλικίας — τα οποία θεωρούνται επεμβατικά και επικίνδυνα για την ιδιωτικότητα — προτείνεται ο περιορισμός της συλλογής δεδομένων ανηλίκων εξαρχής.
Τι είναι τα “dark patterns”
Ένα από τα βασικά ζητήματα που θέλει να αντιμετωπίσει ο DFA είναι τα λεγόμενα “dark patterns”. Πρόκειται για τεχνικές σχεδιασμού που χρησιμοποιούνται από εταιρείες για να επηρεάζουν ή να χειραγωγούν τις αποφάσεις των χρηστών.
Παραδείγματα τέτοιων πρακτικών είναι:
κουμπιά που δυσκολεύουν την απόρριψη cookies,
παραπλανητικές επιλογές συνδρομών,
πολύπλοκες διαδικασίες διαγραφής λογαριασμού,
σχεδιασμός που ωθεί τους χρήστες να μοιράζονται περισσότερα δεδομένα από όσα επιθυμούν.
Οι Οργανώσεις Ψηφιακών Δικαιωμάτων ζητούν σαφή απαγόρευση τέτοιων πρακτικών, καθώς θεωρούν ότι περιορίζουν την ελευθερία επιλογής και υπονομεύουν την αυτονομία των πολιτών στο διαδίκτυο.
Ενίσχυση της κυριαρχίας των χρηστών
Ένα ακόμη σημαντικό ζήτημα αφορά τον έλεγχο που έχουν οι πολίτες πάνω στις ψηφιακές υπηρεσίες και τα προϊόντα που αγοράζουν. Σήμερα, πολλές εταιρείες επιβάλλουν περιορισμούς μέσω ασαφών όρων χρήσης, τεχνικών περιορισμών ή απομακρυσμένου ελέγχου συσκευών και εφαρμογών.
Στην πράξη, αυτό σημαίνει ότι ένας χρήστης μπορεί:
να χάσει πρόσβαση σε ψηφιακό περιεχόμενο που έχει αγοράσει,
να μην μπορεί να επισκευάσει ή να τροποποιήσει μια συσκευή,
να εξαρτάται αποκλειστικά από μία πλατφόρμα ή υπηρεσία.
Οι οργανώσεις ζητούν ο DFA να ενισχύσει το δικαίωμα των χρηστών να ελέγχουν τις ψηφιακές τους συσκευές και υπηρεσίες, να διευκολύνει τη μεταφορά δεδομένων μεταξύ πλατφορμών και να προωθήσει τη διαλειτουργικότητα μεταξύ εφαρμογών και υπηρεσιών.
Μια διαφορετική προσέγγιση για το ψηφιακό μέλλον
Σύμφωνα με τις Οργανώσεις Ψηφιακών Δικαιωμάτων, η ψηφιακή δικαιοσύνη δεν μπορεί να επιτευχθεί μέσω περισσότερης επιτήρησης ή αυστηρότερου ελέγχου των χρηστών. Αντίθετα, απαιτείται ένα πλαίσιο που να ενισχύει:
την ιδιωτικότητα,
την ελευθερία έκφρασης,
τη διαφάνεια,
και την πραγματική δυνατότητα επιλογής.
Ο Νόμος Ψηφιακής Δικαιοσύνης μπορεί να αποτελέσει σημαντική ευκαιρία για την Ευρώπη να δημιουργήσει ένα πιο δίκαιο και ασφαλές ψηφιακό περιβάλλον. Το ερώτημα είναι αν οι τελικές ρυθμίσεις θα περιορίσουν πραγματικά την εξουσία των μεγάλων ψηφιακών πλατφορμών ή αν θα οδηγήσουν σε νέες μορφές ελέγχου και παρακολούθησης των πολιτών.
Η ΤΝ αλλάζει την ταχύτητα και την κλίμακα της απειλής
Η κυβερνοασφάλεια δεν είναι πια μόνο υπόθεση ειδικών που αναζητούν χειροκίνητα αδυναμίες σε κώδικα, δίκτυα και συστήματα. Η Τεχνητή Νοημοσύνη αλλάζει τη φύση του κινδύνου, επειδή μειώνει δραστικά το κόστος γνώσης, χρόνου και δεξιοτήτων που απαιτούνται για μια επίθεση. Μέχρι πρόσφατα, η ανακάλυψη μιας σοβαρής τρωτότητας απαιτούσε βαθιά τεχνική εμπειρία, υπομονή και εξειδικευμένα εργαλεία. Σήμερα, ένα ισχυρό μοντέλο ΤΝ μπορεί να διαβάζει κώδικα, να εντοπίζει ύποπτα μοτίβα, να προτείνει τρόπους εκμετάλλευσης και να βοηθά στη σύνθεση μιας επίθεσης σε φυσική γλώσσα.
Αυτό δεν σημαίνει ότι κάθε χρήστης γίνεται αυτομάτως ικανός κυβερνοεγκληματίας. Σημαίνει όμως ότι το κατώφλι εισόδου πέφτει. Ένας μέτρια καταρτισμένος επιτιθέμενος μπορεί να κινηθεί ταχύτερα. Μια οργανωμένη ομάδα μπορεί να ελέγξει πολύ περισσότερους στόχους. Μια κρατική ή παρακρατική δομή μπορεί να αυτοματοποιήσει έρευνα που παλαιότερα απαιτούσε μεγάλες ομάδες ειδικών. Το αποτέλεσμα είναι ότι το παράθυρο ανάμεσα στην ανακάλυψη μιας αδυναμίας και την εκμετάλλευσή της μικραίνει επικίνδυνα.
Δεν έχουμε μόνο περισσότερες επιθέσεις, έχουμε διαφορετικές επιθέσεις
Η ιδιαιτερότητα της νέας περιόδου δεν είναι απλώς ο αριθμός των επιθέσεων. Είναι ότι η ΤΝ επηρεάζει όλα τα στάδια της αλυσίδας. Μπορεί να βοηθήσει στη δημιουργία πειστικών μηνυμάτων ηλεκτρονικού ψαρέματος στα ελληνικά, με σωστή γλώσσα, ύφος και κοινωνικό πλαίσιο. Μπορεί να αναλύσει δημόσιες πληροφορίες για έναν οργανισμό και να προτείνει πιθανές τεχνικές εισόδου. Μπορεί να γράψει παραλλαγές κακόβουλου κώδικα, να ελέγξει αν ένα σύστημα είναι εκτεθειμένο, να εξηγήσει σφάλματα, να προσαρμόσει εντολές και να επιταχύνει την πειραματική διαδικασία του επιτιθέμενου.
Ταυτόχρονα, η ίδια η ΤΝ εισάγει νέες κατηγορίες τρωτοτήτων. Οι εφαρμογές που βασίζονται σε μεγάλα γλωσσικά μοντέλα μπορεί να υποστούν επιθέσεις μέσω κακόβουλων οδηγιών, διαρροής ευαίσθητων πληροφοριών, δηλητηρίασης δεδομένων εκπαίδευσης ή κακής σύνδεσης με εξωτερικά εργαλεία. Όταν ένα μοντέλο έχει υπερβολικά δικαιώματα, μπορεί να μετατραπεί από βοηθό σε ανεξέλεγκτο μεσάζοντα. Όταν συνδέεται με βάσεις δεδομένων, αποθετήρια κώδικα ή συστήματα παραγωγής χωρίς αυστηρούς περιορισμούς, το λάθος δεν μένει στην οθόνη. Γίνεται επιχειρησιακό συμβάν.
Γιατί το ανοιχτό λογισμικό είναι μέρος της λύσης
Το ανοιχτό λογισμικό δεν είναι μαγική ασπίδα. Κακός κώδικας μπορεί να υπάρχει και σε ανοιχτά έργα. Η διαφορά είναι ότι το ανοιχτό οικοσύστημα επιτρέπει έλεγχο, αναπαραγωγή, διαφάνεια και γρήγορη συλλογική διόρθωση. Στην εποχή της ΤΝ, αυτά τα χαρακτηριστικά γίνονται κρίσιμα.
Πρώτον, η διαφάνεια του κώδικα επιτρέπει σε ερευνητές, πανεπιστήμια, δημόσιους φορείς και εταιρείες να ελέγχουν τι πραγματικά κάνει ένα σύστημα. Σε κρίσιμες υποδομές, όπως υγεία, ενέργεια, μεταφορές, δήμοι και δημόσιες υπηρεσίες, η τυφλή εξάρτηση από κλειστά συστήματα δημιουργεί αδυναμία ελέγχου. Αν δεν ξέρεις τι τρέχεις, δεν μπορείς να το υπερασπιστείς σωστά.
Δεύτερον, το ανοιχτό λογισμικό μειώνει τον αδειοδοτικό εγκλωβισμό. Η κυβερνοασφάλεια δεν πρέπει να εξαρτάται αποκλειστικά από έναν προμηθευτή, ένα κλειστό προϊόν ή μια μη διαφανή πλατφόρμα. Ένας οργανισμός που μπορεί να αλλάξει πάροχο υποστήριξης, να ελέγξει τον κώδικα, να εκπαιδεύσει προσωπικό και να συμβάλει σε διορθώσεις είναι πιο ανθεκτικός.
Τρίτον, τα ανοιχτά εργαλεία επιτρέπουν οικονομικά βιώσιμη άμυνα. Ένας δήμος, ένα πανεπιστήμιο ή μια μικρομεσαία επιχείρηση δεν μπορεί πάντα να αγοράσει ακριβές ιδιόκτητες πλατφόρμες. Μπορεί όμως να στήσει μια αξιόπιστη γραμμή άμυνας με ανοιχτά εργαλεία, αρκεί να υπάρχει τεχνογνωσία, καλή παραμετροποίηση και διαρκής συντήρηση.
Συγκεκριμένα παραδείγματα ανοιχτής άμυνας
Ένα δημόσιο πληροφοριακό σύστημα μπορεί να ξεκινά από υποχρεωτικό κατάλογο εξαρτήσεων λογισμικού, με SBOM σε μορφότυπα όπως SPDX ή CycloneDX. Έτσι, όταν ανακοινώνεται μια σοβαρή τρωτότητα, ο οργανισμός γνωρίζει αμέσως ποια συστήματα επηρεάζονται. Με εργαλεία όπως Trivy ή Grype μπορεί να ελέγχει containers και βιβλιοθήκες. Με Gitleaks μπορεί να εντοπίζει κατά λάθος δημοσιευμένα μυστικά κλειδιά. Με Semgrep μπορεί να εφαρμόζει κανόνες ελέγχου κώδικα σε κάθε αλλαγή πριν αυτή φτάσει στην παραγωγή.
Στην αλυσίδα παραγωγής λογισμικού, εργαλεία και πρακτικές όπως OpenSSF Scorecard, SLSA, Sigstore και Cosign βοηθούν ώστε κάθε πακέτο, container ή βιβλιοθήκη να έχει προέλευση, υπογραφή και ελέγξιμη διαδρομή. Αυτό είναι κρίσιμο όταν η ΤΝ μπορεί να παράγει γρήγορα κώδικα, αλλά και να εισάγει γρήγορα λάθη ή εξαρτήσεις αμφίβολης προέλευσης.
Στην επιχειρησιακή παρακολούθηση, ανοιχτά εργαλεία όπως Wazuh, Zeek, Suricata και Falco μπορούν να καλύψουν τελικά σημεία, δίκτυα και περιβάλλοντα containers. Για ανταλλαγή πληροφοριών απειλών, MISP και OpenCTI επιτρέπουν συνεργασία ανάμεσα σε δημόσιους φορείς, ερευνητικά κέντρα και κοινότητες ασφάλειας. Η ΤΝ μπορεί να προστεθεί πάνω σε αυτά ως βοηθός ανάλυσης συμβάντων, όχι ως ανεξέλεγκτος αυτόματος χειριστής.
Η σωστή πολιτική επιλογή
Η απάντηση στην ΤΝ δεν είναι να κλείσουμε τα συστήματα πίσω από ακόμη περισσότερα μαύρα κουτιά. Είναι να χτίσουμε ανοιχτές, ελέγξιμες και συντηρήσιμες υποδομές. Για την Ελλάδα αυτό σημαίνει δημόσιες προμήθειες με ανοιχτά πρότυπα, υποχρεωτικά SBOM, δημοσίευση κώδικα όπου χρηματοδοτείται από δημόσιο χρήμα, ενίσχυση ελληνικών ομάδων ανοιχτού λογισμικού και δημιουργία εθνικής εφεδρείας κυβερνοασφάλειας με πανεπιστήμια, ερευνητές, επιχειρήσεις και κοινότητες.
Η Τεχνητή Νοημοσύνη θα κάνει τις επιθέσεις ταχύτερες. Μπορεί όμως να κάνει και την άμυνα καλύτερη, αν οι αμυνόμενοι έχουν πρόσβαση σε γνώση, εργαλεία και κώδικα. Η ανοιχτότητα δεν είναι ιδεολογική πολυτέλεια. Είναι πρακτική προϋπόθεση ψηφιακής ανθεκτικότητας.
Η ΤΝ αλλάζει την ταχύτητα και την κλίμακα της απειλής
Η κυβερνοασφάλεια δεν είναι πια μόνο υπόθεση ειδικών που αναζητούν χειροκίνητα αδυναμίες σε κώδικα, δίκτυα και συστήματα. Η Τεχνητή Νοημοσύνη αλλάζει τη φύση του κινδύνου, επειδή μειώνει δραστικά το κόστος γνώσης, χρόνου και δεξιοτήτων που απαιτούνται για μια επίθεση. Μέχρι πρόσφατα, η ανακάλυψη μιας σοβαρής τρωτότητας απαιτούσε βαθιά τεχνική εμπειρία, υπομονή και εξειδικευμένα εργαλεία. Σήμερα, ένα ισχυρό μοντέλο ΤΝ μπορεί να διαβάζει κώδικα, να εντοπίζει ύποπτα μοτίβα, να προτείνει τρόπους εκμετάλλευσης και να βοηθά στη σύνθεση μιας επίθεσης σε φυσική γλώσσα.
Αυτό δεν σημαίνει ότι κάθε χρήστης γίνεται αυτομάτως ικανός κυβερνοεγκληματίας. Σημαίνει όμως ότι το κατώφλι εισόδου πέφτει. Ένας μέτρια καταρτισμένος επιτιθέμενος μπορεί να κινηθεί ταχύτερα. Μια οργανωμένη ομάδα μπορεί να ελέγξει πολύ περισσότερους στόχους. Μια κρατική ή παρακρατική δομή μπορεί να αυτοματοποιήσει έρευνα που παλαιότερα απαιτούσε μεγάλες ομάδες ειδικών. Το αποτέλεσμα είναι ότι το παράθυρο ανάμεσα στην ανακάλυψη μιας αδυναμίας και την εκμετάλλευσή της μικραίνει επικίνδυνα.
Δεν έχουμε μόνο περισσότερες επιθέσεις, έχουμε διαφορετικές επιθέσεις
Η ιδιαιτερότητα της νέας περιόδου δεν είναι απλώς ο αριθμός των επιθέσεων. Είναι ότι η ΤΝ επηρεάζει όλα τα στάδια της αλυσίδας. Μπορεί να βοηθήσει στη δημιουργία πειστικών μηνυμάτων ηλεκτρονικού ψαρέματος στα ελληνικά, με σωστή γλώσσα, ύφος και κοινωνικό πλαίσιο. Μπορεί να αναλύσει δημόσιες πληροφορίες για έναν οργανισμό και να προτείνει πιθανές τεχνικές εισόδου. Μπορεί να γράψει παραλλαγές κακόβουλου κώδικα, να ελέγξει αν ένα σύστημα είναι εκτεθειμένο, να εξηγήσει σφάλματα, να προσαρμόσει εντολές και να επιταχύνει την πειραματική διαδικασία του επιτιθέμενου.
Ταυτόχρονα, η ίδια η ΤΝ εισάγει νέες κατηγορίες τρωτοτήτων. Οι εφαρμογές που βασίζονται σε μεγάλα γλωσσικά μοντέλα μπορεί να υποστούν επιθέσεις μέσω κακόβουλων οδηγιών, διαρροής ευαίσθητων πληροφοριών, δηλητηρίασης δεδομένων εκπαίδευσης ή κακής σύνδεσης με εξωτερικά εργαλεία. Όταν ένα μοντέλο έχει υπερβολικά δικαιώματα, μπορεί να μετατραπεί από βοηθό σε ανεξέλεγκτο μεσάζοντα. Όταν συνδέεται με βάσεις δεδομένων, αποθετήρια κώδικα ή συστήματα παραγωγής χωρίς αυστηρούς περιορισμούς, το λάθος δεν μένει στην οθόνη. Γίνεται επιχειρησιακό συμβάν.
Γιατί το ανοιχτό λογισμικό είναι μέρος της λύσης
Το ανοιχτό λογισμικό δεν είναι μαγική ασπίδα. Κακός κώδικας μπορεί να υπάρχει και σε ανοιχτά έργα. Η διαφορά είναι ότι το ανοιχτό οικοσύστημα επιτρέπει έλεγχο, αναπαραγωγή, διαφάνεια και γρήγορη συλλογική διόρθωση. Στην εποχή της ΤΝ, αυτά τα χαρακτηριστικά γίνονται κρίσιμα.
Πρώτον, η διαφάνεια του κώδικα επιτρέπει σε ερευνητές, πανεπιστήμια, δημόσιους φορείς και εταιρείες να ελέγχουν τι πραγματικά κάνει ένα σύστημα. Σε κρίσιμες υποδομές, όπως υγεία, ενέργεια, μεταφορές, δήμοι και δημόσιες υπηρεσίες, η τυφλή εξάρτηση από κλειστά συστήματα δημιουργεί αδυναμία ελέγχου. Αν δεν ξέρεις τι τρέχεις, δεν μπορείς να το υπερασπιστείς σωστά.
Δεύτερον, το ανοιχτό λογισμικό μειώνει τον αδειοδοτικό εγκλωβισμό. Η κυβερνοασφάλεια δεν πρέπει να εξαρτάται αποκλειστικά από έναν προμηθευτή, ένα κλειστό προϊόν ή μια μη διαφανή πλατφόρμα. Ένας οργανισμός που μπορεί να αλλάξει πάροχο υποστήριξης, να ελέγξει τον κώδικα, να εκπαιδεύσει προσωπικό και να συμβάλει σε διορθώσεις είναι πιο ανθεκτικός.
Τρίτον, τα ανοιχτά εργαλεία επιτρέπουν οικονομικά βιώσιμη άμυνα. Ένας δήμος, ένα πανεπιστήμιο ή μια μικρομεσαία επιχείρηση δεν μπορεί πάντα να αγοράσει ακριβές ιδιόκτητες πλατφόρμες. Μπορεί όμως να στήσει μια αξιόπιστη γραμμή άμυνας με ανοιχτά εργαλεία, αρκεί να υπάρχει τεχνογνωσία, καλή παραμετροποίηση και διαρκής συντήρηση.
Συγκεκριμένα παραδείγματα ανοιχτής άμυνας
Ένα δημόσιο πληροφοριακό σύστημα μπορεί να ξεκινά από υποχρεωτικό κατάλογο εξαρτήσεων λογισμικού, με SBOM σε μορφότυπα όπως SPDX ή CycloneDX. Έτσι, όταν ανακοινώνεται μια σοβαρή τρωτότητα, ο οργανισμός γνωρίζει αμέσως ποια συστήματα επηρεάζονται. Με εργαλεία όπως Trivy ή Grype μπορεί να ελέγχει containers και βιβλιοθήκες. Με Gitleaks μπορεί να εντοπίζει κατά λάθος δημοσιευμένα μυστικά κλειδιά. Με Semgrep μπορεί να εφαρμόζει κανόνες ελέγχου κώδικα σε κάθε αλλαγή πριν αυτή φτάσει στην παραγωγή.
Στην αλυσίδα παραγωγής λογισμικού, εργαλεία και πρακτικές όπως OpenSSF Scorecard, SLSA, Sigstore και Cosign βοηθούν ώστε κάθε πακέτο, container ή βιβλιοθήκη να έχει προέλευση, υπογραφή και ελέγξιμη διαδρομή. Αυτό είναι κρίσιμο όταν η ΤΝ μπορεί να παράγει γρήγορα κώδικα, αλλά και να εισάγει γρήγορα λάθη ή εξαρτήσεις αμφίβολης προέλευσης.
Στην επιχειρησιακή παρακολούθηση, ανοιχτά εργαλεία όπως Wazuh, Zeek, Suricata και Falco μπορούν να καλύψουν τελικά σημεία, δίκτυα και περιβάλλοντα containers. Για ανταλλαγή πληροφοριών απειλών, MISP και OpenCTI επιτρέπουν συνεργασία ανάμεσα σε δημόσιους φορείς, ερευνητικά κέντρα και κοινότητες ασφάλειας. Η ΤΝ μπορεί να προστεθεί πάνω σε αυτά ως βοηθός ανάλυσης συμβάντων, όχι ως ανεξέλεγκτος αυτόματος χειριστής.
Η σωστή πολιτική επιλογή
Η απάντηση στην ΤΝ δεν είναι να κλείσουμε τα συστήματα πίσω από ακόμη περισσότερα μαύρα κουτιά. Είναι να χτίσουμε ανοιχτές, ελέγξιμες και συντηρήσιμες υποδομές. Για την Ελλάδα αυτό σημαίνει δημόσιες προμήθειες με ανοιχτά πρότυπα, υποχρεωτικά SBOM, δημοσίευση κώδικα όπου χρηματοδοτείται από δημόσιο χρήμα, ενίσχυση ελληνικών ομάδων ανοιχτού λογισμικού και δημιουργία εθνικής εφεδρείας κυβερνοασφάλειας με πανεπιστήμια, ερευνητές, επιχειρήσεις και κοινότητες.
Η Τεχνητή Νοημοσύνη θα κάνει τις επιθέσεις ταχύτερες. Μπορεί όμως να κάνει και την άμυνα καλύτερη, αν οι αμυνόμενοι έχουν πρόσβαση σε γνώση, εργαλεία και κώδικα. Η ανοιχτότητα δεν είναι ιδεολογική πολυτέλεια. Είναι πρακτική προϋπόθεση ψηφιακής ανθεκτικότητας.
Πηγές άρθρου:
Anthropic, Project Glasswing: Η ανακοίνωση παρουσιάζει το Project Glasswing και εξηγεί γιατί τα προηγμένα μοντέλα ΤΝ μπορούν να εντοπίζουν και να αξιοποιούν ευπάθειες λογισμικού, αλλά και πώς μπορούν να δοθούν ελεγχόμενα στους αμυνόμενους για την προστασία κρίσιμων υποδομών: https://www.anthropic.com/glasswing,
OpenAI, Scaling Trusted Access for Cyber Defense: Η OpenAI περιγράφει το μοντέλο GPT-5.4-Cyber και το πλαίσιο ελεγχόμενης πρόσβασης για νόμιμους επαγγελματίες κυβερνοασφάλειας, αναδεικνύοντας το δίλημμα ανάμεσα στη χρήσιμη αμυντική ικανότητα και τον κίνδυνο κατάχρησης: https://openai.com/index/scaling-trusted-access-for-cyber-defense/,
OWASP, Top 10 for Large Language Model Applications: Το OWASP καταγράφει βασικούς κινδύνους για εφαρμογές που αξιοποιούν μεγάλα γλωσσικά μοντέλα, όπως prompt injection, δηλητηρίαση δεδομένων, ευπάθειες στην αλυσίδα εφοδιασμού και υπερβολική αυτονομία συστημάτων ΤΝ: https://owasp.org/www-project-top-10-for-large-language-model-applications/,
CISA, Secure by Design: Η CISA τεκμηριώνει την ανάγκη το λογισμικό να σχεδιάζεται με ενσωματωμένη ασφάλεια από την αρχή, με διαφάνεια, λογοδοσία και ευθύνη των κατασκευαστών για την ασφάλεια των χρηστών: https://www.cisa.gov/securebydesign,
OpenSSF, OpenSSF Scorecard: Το OpenSSF Scorecard είναι χαρακτηριστικό παράδειγμα ανοιχτού εργαλείου που αξιολογεί κινδύνους ασφάλειας σε έργα ανοιχτού κώδικα και βοηθά οργανισμούς να ελέγχουν εξαρτήσεις και πρακτικές ανάπτυξης λογισμικού: https://openssf.org/projects/scorecard/.
Η Ευρωπαϊκή Επιτροπή υποστηρίζει ότι ο Κανονισμός για τις Ψηφιακές Αγορές (Digital Markets Act – DMA) είναι «κατάλληλος για τον σκοπό του» και ήδη έχει θετικό αντίκτυπο στις ψηφιακές αγορές της Ευρώπης. Ωστόσο, παρά τις μεγάλες δυνατότητές του, η μέχρι σήμερα εφαρμογή του αποκαλύπτει σοβαρές αδυναμίες. Η χαλαρή επιβολή των κανόνων και οι πολιτικές παρεμβάσεις φαίνεται να επιτρέπουν στις μεγάλες τεχνολογικές πλατφόρμες – τους λεγόμενους gatekeepers – να συνεχίζουν να κυριαρχούν στην ψηφιακή οικονομία.
Ένας ιστορικός νόμος για τις ψηφιακές αγορές
Στις 28 Απριλίου, η Ευρωπαϊκή Επιτροπή δημοσίευσε την πρώτη επίσημη αξιολόγηση του DMA, όπως προβλέπει ο ίδιος ο κανονισμός. Ο DMA θεωρείται ένα από τα σημαντικότερα εργαλεία της Ευρωπαϊκής Ένωσης για τον περιορισμό της δύναμης των μεγάλων τεχνολογικών εταιρειών και για την προστασία του ανταγωνισμού, της ιδιωτικότητας και της ελευθερίας επιλογής των χρηστών.
Ο στόχος του νόμου είναι ξεκάθαρος: να εμποδίσει τις κυρίαρχες ψηφιακές πλατφόρμες να εκμεταλλεύονται τη θέση τους εις βάρος μικρότερων επιχειρήσεων και των ίδιων των καταναλωτών. Για να πετύχει όμως αυτός ο στόχος, απαιτείται όχι μόνο σωστή νομοθεσία αλλά και αποφασιστική εφαρμογή της.
Οι πρώτες επιτυχίες του DMA
Δεν μπορεί να αγνοηθεί ότι ο DMA έχει ήδη επιφέρει ορισμένες σημαντικές αλλαγές. Για παράδειγμα:
Οι χρήστες smartphone στην Ευρώπη βλέπουν πλέον οθόνες επιλογής (choice screens), μέσω των οποίων μπορούν να επιλέγουν ελεύθερα τον browser ή τη μηχανή αναζήτησης που επιθυμούν.
Οι μεγάλες πλατφόρμες υποχρεώνονται να ζητούν τη συγκατάθεση των χρηστών πριν συνδυάσουν προσωπικά δεδομένα από διαφορετικές υπηρεσίες.
Αυτές οι αλλαγές ενισχύουν την ελευθερία επιλογής και την προστασία της ιδιωτικότητας, δύο βασικούς πυλώνες του DMA.
Οι gatekeepers συνεχίζουν να παρακάμπτουν τον νόμο
Παρά τις αρχικές επιτυχίες, πολλές από τις μεγαλύτερες τεχνολογικές εταιρείες κατηγορούνται ότι συνεχίζουν να παραβιάζουν ή να παρακάμπτουν τις υποχρεώσεις του DMA.
Η Apple, για παράδειγμα, εξακολουθεί να διατηρεί αυστηρό έλεγχο στο ποιες εφαρμογές μπορούν να εγκαθίστανται στα iPhone, παρά το γεγονός ότι ο DMA απαιτεί τη δυνατότητα χρήσης ανεξάρτητων app stores και εναλλακτικών τρόπων διανομής εφαρμογών.
Η Google ακολουθεί παρόμοια πρακτική στο Android, ενώ παράλληλα συνεχίζει να δυσκολεύει την αφαίρεση προεγκατεστημένων εφαρμογών από τις συσκευές. Μάλιστα, σύμφωνα με επικριτές της, η εταιρεία επιχειρεί να εκμεταλλευτεί νομικά «παράθυρα», ισχυριζόμενη ότι ο όρος «απεγκατάσταση» δεν σημαίνει πλήρη αφαίρεση εφαρμογών από τη συσκευή.
Επιπλέον, τόσο η Apple όσο και η Google φέρονται να επιβάλλουν νέες χρεώσεις ακόμη και όταν επιτρέπουν εναλλακτικές λύσεις, διατηρώντας στην πράξη τον έλεγχο των οικοσυστημάτων τους.
Το μεγάλο πρόβλημα: αδύναμη εφαρμογή
Το βασικότερο πρόβλημα, σύμφωνα με πολλούς αναλυτές και οργανώσεις ψηφιακών δικαιωμάτων, δεν είναι ο ίδιος ο νόμος αλλά η εφαρμογή του.
Η Ευρωπαϊκή Επιτροπή κατηγορείται ότι προτιμά μια προσέγγιση «ρυθμιστικού διαλόγου» με τις μεγάλες εταιρείες αντί για αυστηρή επιβολή κυρώσεων. Με άλλα λόγια, αντί να απαιτεί άμεση συμμόρφωση, επιλέγει συχνά να διαπραγματεύεται με τους gatekeepers.
Αυτό δημιουργεί την εντύπωση ότι οι μεγάλες τεχνολογικές εταιρείες απολαμβάνουν προνομιακή μεταχείριση που δεν θα είχε καμία άλλη επιχείρηση ή πολίτης σε περίπτωση παραβίασης της νομοθεσίας.
Πολιτικές παρεμβάσεις και ζήτημα αξιοπιστίας
Ανησυχία προκαλούν και οι πληροφορίες ότι η Πρόεδρος της Ευρωπαϊκής Επιτροπής, Ούρσουλα φον ντερ Λάιεν, καθυστέρησε την επιβολή ήδη οριστικοποιημένου προστίμου δισεκατομμυρίων ευρώ κατά της Google.
Αν επιβεβαιωθούν αυτές οι πληροφορίες, θα πρόκειται για σοβαρό πλήγμα στην αξιοπιστία του DMA και συνολικά της ευρωπαϊκής πολιτικής ανταγωνισμού. Η εφαρμογή ενός τόσο σημαντικού νόμου δεν μπορεί να εξαρτάται από πολιτικές ισορροπίες ή πιέσεις.
Η ανεξαρτησία της επιβολής του νόμου είναι κρίσιμη όχι μόνο για την αποτελεσματικότητα του DMA αλλά και για την εμπιστοσύνη των πολιτών στους ευρωπαϊκούς θεσμούς.
Ένα πολιτικό τεστ για την Ευρώπη
Ο DMA αποτελεί ίσως τη σημαντικότερη προσπάθεια της Ευρώπης να περιορίσει τη δύναμη των ψηφιακών κολοσσών και να αποκαταστήσει την ισορροπία στην ψηφιακή οικονομία. Όμως η επιτυχία του δεν θα κριθεί από τις καλές προθέσεις ή τη φιλόδοξη διατύπωση του νόμου, αλλά από το κατά πόσο θα εφαρμοστεί στην πράξη.
Η Ευρωπαϊκή Ένωση βρίσκεται μπροστά σε ένα κρίσιμο πολιτικό τεστ: είτε θα επιβάλει τον DMA με συνέπεια, ανεξαρτησία και αποφασιστικότητα είτε θα επιτρέψει στους gatekeepers να συνεχίσουν να διαμορφώνουν τους κανόνες της ψηφιακής αγοράς προς όφελός τους.
Το μέλλον της ευρωπαϊκής ψηφιακής οικονομίας – αλλά και η εμπιστοσύνη των πολιτών στους δημοκρατικούς θεσμούς – εξαρτώνται σε μεγάλο βαθμό από αυτή την επιλογή.
Η Ολλανδία προχώρησε στη δοκιμαστική έναρξη λειτουργίας της νέας πλατφόρμας αποθετηρίου κώδικα code.overheid.nl, η οποία προορίζεται για τη δημόσια διοίκηση και βασίζεται στο λογισμικό ανοιχτού κώδικα Forgejo. Η πλατφόρμα φιλοξενείται αποκλειστικά από το ίδιο το ολλανδικό κράτος και διαχειρίζεται από το Open Source Programme Office (OSPO) του Υπουργείου Εσωτερικών και Σχέσεων του Βασιλείου.
Η πρωτοβουλία αυτή δημιουργήθηκε ως εναλλακτική λύση απέναντι στις μεγάλες εμπορικές υπηρεσίες φιλοξενίας κώδικα και ελέγχου εκδόσεων, όπως το GitHub ή άλλες αντίστοιχες πλατφόρμες. Το εγχείρημα έχει εμπνευστεί από παρόμοιες ευρωπαϊκές προσπάθειες, όπως η γερμανική πλατφόρμα opencode.de και η ευρωπαϊκή code.europa.eu.
Ψηφιακή Κυριαρχία και Έλεγχος Δεδομένων
Βασικός στόχος της νέας πλατφόρμας είναι η ενίσχυση της ψηφιακής κυριαρχίας και του ελέγχου των δεδομένων του ολλανδικού δημοσίου. Σύμφωνα με τον Boris Van Hoytema, Project Manager του OSPO, η ανάγκη δημιουργίας μιας κρατικά ελεγχόμενης πλατφόρμας προέκυψε από τη νομική απαίτηση το υπουργείο να δημοσιεύει τον πηγαίο του κώδικα σε υποδομή που ανήκει στο ίδιο το κράτος.
Μέχρι σήμερα, πολλοί δημόσιοι οργανισμοί στην Ολλανδία χρησιμοποιούσαν εξωτερικές πλατφόρμες, γεγονός που δημιουργούσε εξαρτήσεις από τρίτους παρόχους και πιθανούς περιορισμούς στο μέλλον. Αντίθετα, το Forgejo είναι μια ελαφριά, αυτο-φιλοξενούμενη πλατφόρμα, επιτρέποντας στην κυβέρνηση να διατηρεί πλήρη έλεγχο της υποδομής και της αξιοπιστίας της υπηρεσίας.
Ενίσχυση της Συνεργασίας στον Δημόσιο Τομέα
Πέρα από τη φιλοξενία ανοιχτού κώδικα, η νέα πλατφόρμα στοχεύει και στην ενίσχυση της συνεργασίας μεταξύ των δημόσιων υπηρεσιών αλλά και με την ευρύτερη κοινότητα προγραμματιστών. Η αρχιτεκτονική του Forgejo επιτρέπει την ομοσπονδιοποίηση αποθετηρίων κώδικα, διευκολύνοντας τη διασύνδεση διαφορετικών φορέων χωρίς εξάρτηση από έναν μόνο πάροχο ή εταιρεία.
Ο Van Hoytema ανέφερε ότι το όραμα της ομάδας είναι η δημιουργία μιας πλήρους πλατφόρμας ανάπτυξης λογισμικού και συνεργασίας για ολόκληρη τη δημόσια διοίκηση. Ήδη, διάφοροι κρατικοί οργανισμοί συμμετέχουν ενεργά στην ανάπτυξη της υπηρεσίας, ενώ η κοινότητα χρηστών καλείται να συμβάλει στη διαμόρφωση των λειτουργιών της πλατφόρμας.
Σταδιακή Υλοποίηση με Έμφαση στις Ανάγκες των Χρηστών
Η ολλανδική κυβέρνηση επέλεξε να προχωρήσει αρχικά σε μια «soft launch» έκδοση της πλατφόρμας, ώστε να δοκιμαστεί στην πράξη και να εξελιχθεί βάσει πραγματικών αναγκών και σχολίων των χρηστών. Η στρατηγική αυτή επιτρέπει τη σταδιακή ανάπτυξη λειτουργιών που θα υποστηρίζουν αποτελεσματικά τις καθημερινές ανάγκες των δημόσιων οργανισμών.
Η πρωτοβουλία της Ολλανδίας αντικατοπτρίζει μια ευρύτερη ευρωπαϊκή τάση προς την υιοθέτηση ανοιχτού λογισμικού και τη δημιουργία ανεξάρτητων ψηφιακών υποδομών, με στόχο τη μείωση της εξάρτησης από μεγάλες τεχνολογικές εταιρείες και την ενίσχυση της διαφάνειας και της ασφάλειας στον δημόσιο τομέα.
Η νέα κούρσα για τον έλεγχο της ψηφιακής οικονομίας
Η συζήτηση για την Τεχνητή Νοημοσύνη παρουσιάζεται συχνά σαν τεχνολογική ιστορία. Στην πραγματικότητα είναι πρωτίστως ιστορία ισχύος, υποδομών και ελέγχου. Οι μεγαλύτερες εταιρείες τεχνολογίας επενδύουν εκατοντάδες δισεκατομμύρια δολάρια τον χρόνο σε υπολογιστικά κέντρα, δίκτυα, ενεργειακές συμφωνίες, ομάδες έρευνας και νέα μοντέλα, παρότι μεγάλο μέρος της παραγωγικής ΤΝ δεν έχει ακόμη σταθερή κερδοφορία. Αυτό φαίνεται παράδοξο μόνο αν βλέπει κανείς την ΤΝ ως ένα απλό προϊόν λογισμικού. Δεν είναι όμως ένα ακόμη πρόγραμμα που πουλιέται με συνδρομή. Είναι η νέα βασική υποδομή πάνω στην οποία ενδέχεται να οργανωθούν η εργασία γνώσης, οι δημόσιες υπηρεσίες, η αναζήτηση πληροφορίας, η εκπαίδευση, η παραγωγή περιεχομένου, η βιομηχανική αυτοματοποίηση και η ίδια η σχέση των πολιτών με τις ψηφιακές υπηρεσίες.
Το οικονομικό στοίχημα των μεγάλων εταιρειών
Οι μεγάλες εταιρείες δεν επενδύουν σήμερα επειδή η ΤΝ είναι ήδη εξαιρετικά κερδοφόρα. Επενδύουν επειδή φοβούνται ότι, αν δεν το κάνουν, θα χάσουν τον έλεγχο της επόμενης ψηφιακής πλατφόρμας. Στην προηγούμενη φάση του διαδικτύου, ο έλεγχος ανήκε σε λίγες πλατφόρμες: αναζήτηση, κοινωνικά δίκτυα, λειτουργικά συστήματα κινητών, ηλεκτρονικό εμπόριο, υπολογιστικό νέφος. Στη νέα φάση, πλατφόρμα μπορεί να γίνει ο πράκτορας ΤΝ που απαντά, γράφει, προτείνει, αγοράζει, οργανώνει και εκτελεί εντολές για λογαριασμό του χρήστη. Όποιος ελέγχει αυτό το επίπεδο, δεν πουλά απλώς μια υπηρεσία. Μεσολαβεί ανάμεσα στον πολίτη, την επιχείρηση, το κράτος και την πληροφορία.
Γι’ αυτό η κούρσα έχει χαρακτηριστικά στρατηγικής άμυνας. Η Google δεν μπορεί να αφήσει την αναζήτηση να αντικατασταθεί από βοηθούς ΤΝ τρίτων. Η Microsoft δεν μπορεί να επιτρέψει να χαθεί η θέση της στο λογισμικό γραφείου και στο εταιρικό νέφος. Η Amazon δεν μπορεί να χάσει τη ζήτηση για υπολογιστική ισχύ. Η Meta δεν θέλει να εξαρτηθεί από μοντέλα τρίτων για τις δικές της πλατφόρμες. Οι εταιρείες παραγωγής μοντέλων, όπως η OpenAI, η Anthropic και η xAI, προσπαθούν να γίνουν το βασικό λειτουργικό επίπεδο της νέας οικονομίας. Η σημερινή ζημία αντιμετωπίζεται ως τίμημα εισόδου σε μια αγορά που, αν παγιωθεί ολιγοπωλιακά, μπορεί να αποδώσει πολύ μεγαλύτερες προσόδους στο μέλλον.
Υποδομή πριν από την κερδοφορία
Το μεγαλύτερο μέρος της δαπάνης δεν αφορά μόνο την εκπαίδευση μοντέλων. Αφορά τη δημιουργία φυσικής υποδομής: υπολογιστικά κέντρα, επεξεργαστές, μνήμη, δίκτυα, ψύξη, ηλεκτρική ενέργεια, γη, μακροχρόνια συμβόλαια και εξειδικευμένο προσωπικό. Αυτή η υποδομή έχει τεράστιο κόστος, αλλά δημιουργεί και εμπόδιο εισόδου. Όσο ακριβότερη γίνεται η ΤΝ, τόσο λιγότεροι μπορούν να συμμετάσχουν. Η αγορά της ΤΝ κινδυνεύει έτσι να ακολουθήσει τη γνωστή πορεία των ψηφιακών αγορών: πρώτα έντονος ανταγωνισμός, μετά συγκέντρωση, στη συνέχεια εξάρτηση των χρηστών και των επιχειρήσεων από λίγους παρόχους.
Υπάρχει, βέβαια, και ο κίνδυνος της «παραγωγικής φούσκας». Η ιστορία των σιδηροδρόμων, των τηλεπικοινωνιακών δικτύων και του διαδικτύου δείχνει ότι μια τεχνολογική υπερεπένδυση μπορεί να καταστρέψει κεφάλαια και εταιρείες, αλλά να αφήσει πίσω χρήσιμες υποδομές. Το ερώτημα δεν είναι μόνο αν η ΤΝ θα είναι χρήσιμη. Ήδη είναι χρήσιμη σε πολλές εργασίες. Το ερώτημα είναι ποιος θα εισπράξει την αξία, με τι κόστος για την κοινωνία και με ποιο βαθμό εξάρτησης.
Γιατί η Ευρώπη δεν πρέπει να αντιγράψει το αμερικανικό μοντέλο
Για τα κράτη μέλη της Ευρωπαϊκής Ένωσης, η απάντηση δεν μπορεί να είναι η απλή αντιγραφή της αμερικανικής κούρσας κεφαλαίου. Η Ευρώπη δεν έχει την ίδια συγκέντρωση τεχνολογικών μονοπωλίων, ούτε την ίδια ανοχή σε υποδομές που λειτουργούν ως ιδιωτικά κλειστά οικοσυστήματα. Το ευρωπαϊκό συμφέρον βρίσκεται σε διαφορετική κατεύθυνση: ανοιχτά πρότυπα, ελεγχόμενες υποδομές, διαφάνεια, διαλειτουργικότητα, προστασία δεδομένων, δημόσια επένδυση που παράγει δημόσια τεχνογνωσία και όχι μόνιμη εξάρτηση.
Εδώ τα χαμηλού κόστους τοπικά μοντέλα ανοιχτού λογισμικού αποκτούν ιδιαίτερη σημασία. Δεν είναι πανάκεια και δεν αντικαθιστούν τα μεγαλύτερα μοντέλα σε κάθε χρήση. Δεν μπορούν εύκολα να ανταγωνιστούν τα ακριβότερα κλειστά μοντέλα στην πιο απαιτητική πολυτροπική παραγωγή, στην αιχμή της έρευνας ή σε γενικού σκοπού πράκτορες μεγάλης πολυπλοκότητας. Μπορούν όμως να καλύψουν μεγάλο μέρος των πραγματικών αναγκών του Δημοσίου, των μικρομεσαίων επιχειρήσεων, της εκπαίδευσης και πολλών επαγγελματικών κλάδων, ιδίως όταν συνδυάζονται με καλά οργανωμένα δεδομένα, ανάκτηση γνώσης από έγγραφα και ανθρώπινη εποπτεία.
Πού μπορούν να δώσουν λύση τα τοπικά ανοιχτά LLMs
Στον δημόσιο τομέα, τοπικά μοντέλα μπορούν να χρησιμοποιηθούν για αναζήτηση σε κανονιστικά κείμενα, περίληψη εγγράφων, προετοιμασία απαντήσεων, ταξινόμηση αιτημάτων, υποστήριξη υπαλλήλων και πολυγλωσσική εξυπηρέτηση, χωρίς να μεταφέρονται ευαίσθητα δεδομένα σε εξωτερικές πλατφόρμες. Στην υγεία, μπορούν να στηρίξουν διοικητικές εργασίες, ανωνυμοποίηση, κλινική τεκμηρίωση και εσωτερική αναζήτηση, με αυστηρά όρια και χωρίς αυτόματες αποφάσεις. Στην εκπαίδευση, μπορούν να προσφέρουν ασφαλή περιβάλλοντα μάθησης, προσαρμοσμένα στην ελληνική και στις άλλες ευρωπαϊκές γλώσσες, με παιδαγωγική εποπτεία. Στον πολιτισμό και στον τουρισμό, μπορούν να βοηθήσουν στην τεκμηρίωση αρχείων, στη μετάφραση, στην προσβασιμότητα και στη δημιουργία ψηφιακών υπηρεσιών γύρω από τη γλώσσα και την κληρονομιά. Στη μεταποίηση, στην ενέργεια, στην αγροδιατροφή, στη ναυτιλία και στις χρηματοπιστωτικές υπηρεσίες, μπορούν να ενσωματωθούν σε εσωτερικές ροές εργασίας, τεχνική υποστήριξη, συμμόρφωση, συντήρηση και ανάλυση δεδομένων.
Το κρίσιμο πλεονέκτημα δεν είναι μόνο το χαμηλότερο κόστος. Είναι ο έλεγχος. Ένας οργανισμός που λειτουργεί τοπικά ένα ανοιχτό μοντέλο γνωρίζει πού βρίσκονται τα δεδομένα του, μπορεί να προσαρμόσει το σύστημα στη δική του ορολογία, μπορεί να ελέγξει τις εκδόσεις, να αλλάξει πάροχο υποστήριξης και να χτίσει εσωτερική τεχνογνωσία. Η δαπάνη παύει να είναι απλή συνδρομή σε ξένη πλατφόρμα και γίνεται επένδυση σε τεχνογνωσία.
Η στρατηγική επιλογή
Η ΤΝ δεν θα κριθεί μόνο από το ποιο μοντέλο απαντά καλύτερα σε μια επίδειξη. Θα κριθεί από το ποια αρχιτεκτονική υπηρετεί την οικονομία και τη δημοκρατία. Για την Ευρώπη, η πιο ώριμη στρατηγική είναι διπλή: πρόσβαση σε ισχυρές δημόσιες και ευρωπαϊκές υποδομές για έρευνα και απαιτητικές εφαρμογές, και ταυτόχρονα μαζική υιοθέτηση τοπικών, ανοιχτών, χαμηλού κόστους μοντέλων για τις καθημερινές ανάγκες οργανισμών και επιχειρήσεων. Έτσι η ΤΝ μπορεί να γίνει παραγωγικό εργαλείο και όχι νέος μηχανισμός αδειοδοτικού εγκλωβισμού. Το διακύβευμα δεν είναι αν θα χρησιμοποιήσουμε ΤΝ. Το διακύβευμα είναι αν θα τη χρησιμοποιήσουμε ως δημόσια και παραγωγική υποδομή ή ως ακόμη μία εξάρτηση από λίγους παγκόσμιους ιδιοκτήτες της υπολογιστικής ισχύος.
DeepSeek AI, “DeepSeek-R1”: Παράδειγμα ανοιχτού μοντέλου συλλογισμού που έδειξε ότι η υψηλή απόδοση δεν απαιτεί κατ’ ανάγκη αποκλειστικά κλειστές και υπερβολικά ακριβές αρχιτεκτονικές, ενισχύοντας τη συζήτηση για αποδοτικότερα μοντέλα: https://github.com/deepseek-ai/DeepSeek-R1,
EuroHPC Joint Undertaking, “AI Factories”: Το επίσημο ευρωπαϊκό πλαίσιο για πρόσβαση ερευνητών, επιχειρήσεων και νεοφυών εταιρειών σε υπερυπολογιστικές υποδομές ΤΝ, με στόχο την ενίσχυση της ευρωπαϊκής τεχνολογικής κυριαρχίας: https://www.eurohpc-ju.europa.eu/ai-factories_en,
European Commission, “Apply AI Strategy”: Η στρατηγική της Ευρωπαϊκής Επιτροπής για την υιοθέτηση της ΤΝ σε στρατηγικούς τομείς της οικονομίας και του δημόσιου τομέα, με έμφαση στην ανταγωνιστικότητα, στις ΜμΕ και στην τεχνολογική κυριαρχία της Ευρώπης: https://digital-strategy.ec.europa.eu/en/policies/apply-ai .
Στις 23 Απριλίου 2026 η Canonical, η εταιρία πίσω από το Ubuntu, κυκλοφόρησε την έκδοση Ubuntu 26.04 με κωδική ονομασία Resolute Raccoon. Η έκδοση αυτή είναι έκδοση με υποστήριξη μακράς διάρκειας (LTS), δηλαδή θα υποστηρίζεται με ενημερώσεις ασφαλείας έως και
Η Google ανακοίνωσε τους επιλεγμένους οργανισμούς για το Google Summer of Code 2026 (GSoC 2026), και ανάμεσά τους συγκαταλέγεται για ακόμη μία χρονιά ο Οργανισμός Ανοιχτών Τεχνολογιών – ΕΕΛΛΑΚ
H ΕΕΛΛΑΚ συμμετέχει ως mentor organization στο πρόγραμμα, υποστηρίζοντας έργα ανοιχτού κώδικα που θα υλοποιηθούν από φοιτητές, ερευνητές και νέους προγραμματιστές από όλο τον κόσμο κατά τη διάρκεια του καλοκαιριού του 2026. Οι συμμετέχοντες που θα ολοκληρώσουν επιτυχώς το πρόγραμμα θα λάβουν αμοιβή έως 3.600$ για τη συνεισφορά τους.
Φέτος, η ΕΕΛΛΑΚ συμμετέχει με 7 έργα ανοιχτού κώδικα, που καλύπτουν ένα ευρύ φάσμα τομέων: από την Τεχνητή Νοημοσύνη και την επεξεργασία φυσικής γλώσσας, έως τις διαστημικές εφαρμογές, την εκπαιδευτική ρομποτική και την ασφάλεια λογισμικού. Η πλήρης λίστα των έργων είναι διαθέσιμη στη σελίδα του ΕΕΛΛΑΚ στο GSoC 2026.
Τα 7 έργα ανοιχτού κώδικα
1. VS Code Plugin για το CScout
Στόχος του έργου είναι η δημιουργία ενός plugin για το Visual Studio Code που θα λειτουργεί ως γραφικό περιβάλλον για το CScout, ένα εργαλείο ανάλυσης και αναπαραγωγής (refactoring) κώδικα C. Το CScout μπορεί να αναλύσει μεγάλα projects εκατομμυρίων γραμμών κώδικα (όπως τον πυρήνα Linux ή τον Apache), αλλά η χρήση του παραμένει δύσκολη χωρίς γραφικό περιβάλλον. Το plugin θα φέρει τα αποτελέσματα ανάλυσης απευθείας μέσα στον editor, μειώνοντας σημαντικά το εμπόδιο υιοθέτησης του εργαλείου από developers. Mentor: Diomidis Spinellis
2. OpenTRIM – Βελτίωση Προσομοίωσης Ιόντων σε Υλικά
Το OpenTRIM είναι ένα ανοιχτού κώδικα πλαίσιο Monte Carlo για την προσομοίωση της διέλευσης ενεργητικών ιόντων μέσα σε υλικά και τον υπολογισμό των αντίστοιχων βλαβών. Φέτος το έργο στοχεύει στην ανάπτυξη ενός εργαλείου 3D οπτικοποίησης σε πραγματικό χρόνο για τα ιοντικά ίχνη που παράγει η προσομοίωση, καθώς και στη δημιουργία Python bindings ώστε η εκτέλεση προσομοιώσεων να γίνεται απευθείας από Python. Mentors: George Apostolopoulos, Michail Axiotis, Eleni Mitsi
3.GlossAPI: ML-assisted Anonymization Layer and Targeted Pipeline Improvements for Greek Datasets
Τα ελληνικά δημόσια datasets, όπως αυτά του OpenGov, περιέχουν συχνά προσωπικά δεδομένα που πρέπει να αφαιρεθούν για τη συμμόρφωση με τον GDPR. Η αυτόματη ανωνυμοποίηση ελληνικού κειμένου είναι ιδιαίτερα απαιτητική λόγω της πολυπλοκότητας της γλώσσας και των σφαλμάτων OCR που εμφανίζονται συχνά στα έγγραφα. Το project αναπτύσσει ένα αυτόνομο εργαλείο ανωνυμοποίησης που ενσωματώνεται στο pipeline του GlossAPI, συνδυάζοντας γρήγορες κανονικές εκφράσεις και προσαρμοσμένα λεξικά για τυπικές πληροφορίες. Το σύνολο θα εκτίθεται μέσω ενός απλού FastAPI REST interface, διατηρώντας τον κύριο κώδικα του GlossAPI καθαρό και ανεξάρτητο. Contributor: George Sotiropoulos | Mentors: Nikos Tsekos, Myrsini Ioannou, Dimitrios Athanasopoulos, Panagiotis Skarvelis
4. Command & Data Handling Software για CubeSat FlatSat Testbed
Το έργο εστιάζει στην ανάπτυξη λογισμικού διαχείρισης εντολών και δεδομένων (C&DH flight software) για ένα ανοιχτής αρχιτεκτονικής δοκιμαστικό περιβάλλον CubeSat. Πρόκειται για μια ground-based πλατφόρμα ανάπτυξης και δοκιμών αλγορίθμων AI επί του σκάφους, κατάλληλη για φοιτητικά projects και μελλοντικές ανοιχτές αποστολές CubeSat. Το λογισμικό θα υλοποιηθεί σε STM32 με FreeRTOS και θα ακολουθεί αρχιτεκτονική εμπνευσμένη από το NASA cFS. Mentors: Christos Chronis, Simon Vellas
5. Fine-tuning Μοντέλων AI για Δημοτικά Συμβούλια
Το έργο αξιοποιεί την πλατφόρμα OpenCouncil — ένα civic tech εργαλείο που κάνει τις συνεδριάσεις ελληνικών δημοτικών συμβουλίων προσβάσιμες στους πολίτες μέσω AI μεταγραφής και αναζήτησης. Με εκατοντάδες ώρες ηχογραφήσεων και ανθρώπινα διορθωμένα transcripts από 10+ δήμους, το project στοχεύει στο fine-tuning του μοντέλου Whisper ώστε να βελτιωθεί σημαντικά η ακρίβεια μεταγραφής για ελληνική διοικητική ορολογία, τοπικές διαλέκτους και πολλαπλούς ομιλητές. Το αποτέλεσμα θα δημοσιευθεί ανοιχτά, ωφελώντας ολόκληρη την ελληνόφωνη κοινότητα NLP. Mentors: Andreas Kouloumos, Christos Porios
6.Unified SBOM Management via RDF Database Abstraction
Το έργο αντιμετωπίζει την πρόκληση διαχείρισης δεδομένων Software Bill of Materials (SBOM) σε μεγάλη κλίμακα. Τα SBOMs σε μορφή SPDX είναι κρίσιμα για την ασφάλεια της αλυσίδας εφοδιασμού λογισμικού, αλλά οι υπάρχουσες λύσεις βασισμένες σε αρχεία δεν επαρκούν για σύνθετη ανάλυση. Το project αναπτύσσει εργαλεία που αξιοποιούν RDF triplestores και ερωτήματα SPARQL, παραμένοντας database-agnostic με υποστήριξη πολλαπλών backends. Τα παραδοτέα περιλαμβάνουν εργαλεία εισαγωγής/εξαγωγής SPDX εγγράφων, βοηθητικά εργαλεία CRUD και τεκμηρίωση. Contributor: Maira Papadopoulou | Mentor: Alexios Zavras
7. FOSSBot Platform: Βελτιώσεις Προσομοίωσης και Ενσωμάτωση AI
Το FOSSBot είναι μια ανοιχτή ρομποτική πλατφόρμα με εκπαιδευτικό προσανατολισμό. Φέτος το project στοχεύει στην ενίσχυση του περιβάλλοντος προσομοίωσης ρομπότ με AI-driven δυνατότητες και βελτιωμένο ρεαλισμό, εστιάζοντας στη διαλειτουργικότητα, την επεκτασιμότητα και την αναπαραγωγιμότητα μέσα σε ανοιχτά οικοσυστήματα. Το αποτέλεσμα θα περιλαμβάνει βελτιωμένα simulation modules, AI components για αυτόνομη λήψη αποφάσεων και παραδείγματα χρήσης για εκπαίδευση και έρευνα. Mentors: Christos Chronis, Eleftheria Papageorgiou, Irida Ntinou
Η ΕΕΛΛΑΚ και το GSoC
Ο Οργανισμός Ανοιχτών Τεχνολογιών – ΕΕΛΛΑΚ συμμετέχει στο Google Summer of Code εδώ και πολλά χρόνια, αποτελώντας έναν από τους πιο σταθερούς Ελληνικούς φορείς στο πρόγραμμα. Μέσα από αυτή τη συμμετοχή, υποστηρίζει νέους προγραμματιστές να συνεισφέρουν σε πραγματικά έργα ανοιχτού λογισμικού, αποκτώντας εμπειρία σε επαγγελματικά περιβάλλοντα ανάπτυξης. Τα φετινά 7 έργα αντικατοπτρίζουν τον πολυδιάστατο χαρακτήρα του οργανισμού: από την επιστήμη υλικών και τις διαστημικές τεχνολογίες, έως την ψηφιακή διακυβέρνηση και την εκπαίδευση.
Οι εκδηλώσεις δεν σταματούν καθώς αυτήν την εβδομάδα πραγματοποιούνται εκδηλώσεις στην Ελλάδα και στο εξωτερικό για τις ανοιχτές τεχνολογίες και την καινοτομία! Ο Οργανισμός Ανοιχτών Τεχνολογιών (ΕΕΛΛΑΚ) σας προτείνει να τις παρακολουθήσετε και να τις διαδώσετε. Μπορείτε επίσης να δείτε περισσότερες εκδηλώσεις για τις επόμενες εβδομάδες ή να καταχωρίσετε τη δική σας εκδήλωση στο: https://ellak.gr/events.
Αν διαχειρίζεστε υπηρεσίες στον δικό σας server — είτε πρόκειται για Nextcloud, Audiobookshelf, Plex, Proxmox ή οτιδήποτε άλλο — γνωρίζετε πόσο σημαντικό είναι να μαθαίνετε αμέσως όταν κάτι πάει στραβά. Η αναμονή να ανακαλύψετε τυχαία ότι μια υπηρεσία «έπεσε» δεν είναι διαχείριση — είναι τύχη.
Σε αυτό το άρθρο θα δούμε πώς να συνδέσουμε το Uptime Kuma v2 με το Nextcloud Talk, ώστε κάθε φορά που μια υπηρεσία αποτυγχάνει ή ανακάμπτει, να λαμβάνετε αυτόματη ειδοποίηση απευθείας σε μια συνομιλία του Talk. Όλα αυτά χωρίς εξωτερικές υπηρεσίες, χωρίς συνδρομές, 100% open source.
🐻 Τι είναι το Uptime Kuma;
Το Uptime Kuma είναι ένα ελεύθερο, ανοιχτού κώδικα εργαλείο παρακολούθησης υπηρεσιών (monitoring), εμπνευσμένο από υπηρεσίες όπως το UptimeRobot. Διαθέτει φιλικό web interface μέσω του οποίου μπορείτε να παρακολουθείτε HTTP endpoints, TCP ports, DNS, υπηρεσίες Docker, ping και πολλά ακόμα. Το Uptime Kuma v2 — που κυκλοφόρησε το 2025 — έφερε σημαντικές βελτιώσεις στη βάση δεδομένων, στα notifications και, μεταξύ άλλων, ενσωματωμένη υποστήριξη για Nextcloud Talk ως πάροχο ειδοποιήσεων. Τρέχει εύκολα μέσω Docker και αποτελεί την ιδανική επιλογή για αυτόνομες εγκαταστάσεις.
Πώς λειτουργεί η ενσωμάτωση
Η επικοινωνία μεταξύ Uptime Kuma και Nextcloud Talk γίνεται μέσω ενός Talk Bot: το Uptime Kuma στέλνει HTTP αιτήματα υπογεγραμμένα με ένα shared secret απευθείας στο Talk API, και το bot δημοσιεύει το μήνυμα στην επιλεγμένη συνομιλία. Δεν απαιτείται κανένας ενδιάμεσος server ή webhook service.
Uptime Kuma
│
│ HTTP αίτημα (υπογεγραμμένο με HMAC-SHA256)
▼ Nextcloud Talk Bot API
│
▼ Talk conversation (π.χ. infra-alerts)
Τα μηνύματα που λαμβάνετε έχουν αυτή τη μορφή:
[Metabase] 🔴 Down — Request failed with status code 502
[Metabase] ✅ Up — 200 OK
Προαπαιτούμενα
Πριν ξεκινήσουμε, βεβαιωθείτε ότι έχετε:
Nextcloud 32.x εγκατεστημένο μέσω Nextcloud AIO (All-in-One Docker)
Την εφαρμογή Nextcloud Talk εγκατεστημένη και ενεργοποιημένη
Uptime Kuma v2 σε λειτουργία (π.χ. μέσω Docker)
Διαχειριστική πρόσβαση στο Nextcloud (admin account)
Πρόσβαση σε τερματικό SSH στον server σας
⚠️ Σημείωση για το Talk Bot API: Το Nextcloud Talk Bot API απαιτεί ελάχιστο Talk 17.1 (συμβατό με Nextcloud 27.1+). Στο Nextcloud 32 είναι πλήρως διαθέσιμο. Για λόγους ασφαλείας, τα bots μπορούν να εγκατασταθούν μόνο μέσω γραμμής εντολών (occ commands) — δεν υπάρχει γραφική διεπαφή εγκατάστασης bot.
1
Δημιουργία συνομιλίας στο Nextcloud Talk
Το πρώτο βήμα είναι να δημιουργήσουμε μια αποκλειστική συνομιλία (conversation / room) στο Talk, μέσα στην οποία θα αποστέλλονται οι ειδοποιήσεις monitoring. Συνιστούμε να μην χρησιμοποιείτε υπάρχουσα ομαδική συνομιλία, για να κρατάτε τις ειδοποιήσεις οργανωμένες.
Συνδεθείτε στη διεπαφή web του Nextcloud.
Ανοίξτε την εφαρμογή Talk.
Κάντε κλικ στο «Νέα συνομιλία» (New conversation).
Δώστε ένα περιγραφικό όνομα, π.χ. infra-alerts ή monitoring.
Δημιουργήστε τη συνομιλία.
2
Εύρεση του Conversation Token
Κάθε συνομιλία στο Talk ταυτοποιείται με ένα μοναδικό token που εμφανίζεται στη διεύθυνση URL της συνομιλίας. Αυτό το token θα το χρειαστούμε αργότερα για να «πούμε» στο Uptime Kuma πού να στέλνει τις ειδοποιήσεις.
Αφού ανοίξετε τη νέα συνομιλία, κοιτάξτε τη διεύθυνση URL στον browser σας. Θα μοιάζει κάπως έτσι:
https://cloud.example.com/call/abcd1234
Το τμήμα μετά το /call/ είναι το Conversation Token — στο παράδειγμά μας το abcd1234. Αντιγράψτε το και κρατήστε το.
3
Δημιουργία του Talk Bot
Τώρα πρέπει να δημιουργήσουμε το bot που θα στέλνει μηνύματα στη συνομιλία. Αυτό γίνεται αποκλειστικά μέσω γραμμής εντολών, μέσα στο Docker container του Nextcloud AIO.
Το Nextcloud Talk προσφέρει δύο εντολές για τη δημιουργία bot:
talk:bot:create — δημιουργεί bot με αυτόματα παραγόμενο secret, με τη δυνατότητα response μόνο (το bot μπορεί να στέλνει μηνύματα στο chat).
talk:bot:install — πιο προχωρημένη εντολή που απαιτεί και webhook URL, για bots που θέλουν επίσης να λαμβάνουν μηνύματα.
Για το Uptime Kuma, αρκεί η talk:bot:create, γιατί το bot μόνο αποστέλλει ειδοποιήσεις — δεν χρειάζεται να λαμβάνει ή να απαντά σε μηνύματα. Εκτελέστε την παρακάτω εντολή:
Αν δεν ορίσετε secret, το Nextcloud θα δημιουργήσει αυτόματα ένα τυχαίο string 64 χαρακτήρων. Το αποτέλεσμα θα μοιάζει κάπως έτσι:
Bot created successfully
Bot ID: 16
Secret: 3cfa8b8c5e4e1f7b7d2c2a0c0a9c0e4f7c8a3b9e2d1c6f5a4b3c2d1e0f9a8b7
✅ Σημαντικό: Αποθηκεύστε αμέσως το Bot ID και το Bot Secret. Το secret δεν εμφανίζεται ξανά από το σύστημα — αν το χάσετε, πρέπει να διαγράψετε και να ξαναδημιουργήσετε το bot.
4
Προσθήκη του Bot στη συνομιλία
Το bot δημιουργήθηκε στο σύστημα, αλλά δεν έχει ακόμα πρόσβαση σε καμία συνομιλία. Πρέπει να το «συνδέσουμε» με τη συνομιλία που δημιουργήσαμε. Αυτό γίνεται με την εντολή talk:bot:setup, η οποία δέχεται το Bot ID και το Conversation Token:
ID | Name | features 16 | Uptime Kuma Bot | response
Η στήλη features δείχνει response, που σημαίνει ότι το bot μπορεί να δημοσιεύει μηνύματα στις συνομιλίες — ακριβώς αυτό που χρειαζόμαστε για το Uptime Kuma.
Μπορείτε επίσης να φιλτράρετε τη λίστα για μια συγκεκριμένη συνομιλία περνώντας το token ως παράμετρο: php occ talk:bot:list abcd1234. Αυτό είναι χρήσιμο αν έχετε πολλά bots και θέλετε να δείτε ποια είναι ενεργά σε συγκεκριμένη συνομιλία.
6
Ρύθμιση notification στο Uptime Kuma
Ανοίξτε τη web διεπαφή του Uptime Kuma και μεταβείτε στις ρυθμίσεις ειδοποιήσεων:
⚙️ Settings → Notifications → Add New Notification
Στη λίστα τύπων notification, επιλέξτε «Nextcloud Talk». Θα εμφανιστεί φόρμα με τα εξής πεδία:
Πεδίο
Τιμή
Σχόλιο
Friendly Name
Nextcloud Talk Alerts
Όνομα ειδοποίησης (εσωτερικό στο Uptime Kuma)
Nextcloud Host
https://cloud.example.com
Η διεύθυνση του Nextcloud σας (χωρίς trailing slash)
Conversation Token
abcd1234
Το token από το Βήμα 2
Bot Secret
3cfa8b8c5e4e1f7b...
Το secret από το Βήμα 3
Αποθηκεύστε τη ρύθμιση κάνοντας κλικ στο «Save».
7
Δοκιμή της ειδοποίησης
Κάντε κλικ στο κουμπί «Test» δίπλα στη νέα ειδοποίηση. Αν όλα έχουν ρυθμιστεί σωστά, σε λίγα δευτερόλεπτα θα εμφανιστεί ένα δοκιμαστικό μήνυμα στη συνομιλία του Talk:
My Nextcloud Talk Alert Testing
Αν δεν εμφανιστεί μήνυμα, ελέγξτε:
Ότι το Bot Secret που πληκτρολογήσατε είναι ακριβώς το ίδιο με αυτό που παράχθηκε (χωρίς κενά).
Ότι το Conversation Token αντιστοιχεί στη σωστή συνομιλία.
Ότι η διεύθυνση Nextcloud Host είναι προσβάσιμη από τον server του Uptime Kuma (DNS, firewall, κ.λπ.).
Ότι εκτελέσατε το talk:bot:setup με το σωστό token.
8
Ανάθεση της ειδοποίησης σε monitors
Η ειδοποίηση δεν ενεργοποιείται αυτόματα για όλα τα monitors. Πρέπει να την αναθέσετε ξεχωριστά σε κάθε monitor που θέλετε να παρακολουθείτε:
Ανοίξτε ένα monitor στο Uptime Kuma.
Κάντε κλικ στο «Edit».
Κυλήστε κάτω στην ενότητα «Notifications».
Επιλέξτε «Nextcloud Talk Alerts» (ή το όνομα που δώσατε).
Αποθηκεύστε τις αλλαγές.
Από εδώ και πέρα, κάθε φορά που η κατάσταση αυτού του monitor αλλάζει (Down ↔ Up), το Uptime Kuma θα στέλνει αυτόματα ειδοποίηση στο Talk.
💡 Συμβουλές για καλύτερες ειδοποιήσεις
Η ποιότητα μιας ειδοποίησης εξαρτάται σε μεγάλο βαθμό από το όνομα που δίνετε στο monitor. Αντί για γενικά ονόματα όπως «Server 1» ή «HTTP Check», χρησιμοποιήστε περιγραφικά ονόματα που σας λένε αμέσως ποια υπηρεσία επηρεάζεται. Χρήση emoji βοηθά στην οπτική γρήγορη αναγνώριση:
# Πλήρης απεγκατάσταση bot από το σύστημα php occ talk:bot:uninstall 16
Θυμηθείτε να προσθέτετε πάντα το prefix sudo docker exec -it nextcloud-aio-nextcloud πριν από κάθε php occ ... εντολή όταν χρησιμοποιείτε Nextcloud AIO.
Συμπέρασμα
Η ενσωμάτωση Uptime Kuma v2 με Nextcloud Talk είναι μια 100% open source, self-hosted λύση που σας επιτρέπει να λαμβάνετε ειδοποιήσεις monitoring απευθείας στο chat σας — χωρίς εξωτερικές υπηρεσίες, χωρίς κόστος.
Με λίγες εντολές OCC και μια σύντομη ρύθμιση στο Uptime Kuma, έχετε ένα πλήρες σύστημα ειδοποιήσεων που σας ενημερώνει αμέσως για κάθε αλλαγή κατάστασης στις υπηρεσίες σας.
Η τεχνητή νοημοσύνη εντυπωσιάζει γιατί υπολογίζει, ταξινομεί, αναζητά μοτίβα, παράγει κείμενα, εικόνες και απαντήσεις με ταχύτητα που ξεπερνά κάθε ανθρώπινη δυνατότητα. Αυτό όμως δεν σημαίνει ότι βρίσκεται πάνω στην ίδια κλίμακα με την ανθρώπινη νόηση, απλώς σε υψηλότερη βαθμίδα. Δεν έχουμε έναν κοινό άξονα όπου από τη μία πλευρά βρίσκεται ο μαθητής, πιο πάνω ο δάσκαλος και ακόμη πιο πάνω το σύστημα τεχνητής νοημοσύνης. Έχουμε δύο διαφορετικές δομές.
Η ανθρώπινη σκέψη δεν είναι μόνο επεξεργασία πληροφορίας. Είναι μνήμη, εμπειρία, σώμα, συναίσθημα, γλώσσα, κοινωνική σχέση, αμφιβολία, ηθική κρίση, ευθύνη. Μαθαίνουμε επειδή δοκιμάζουμε, αποτυγχάνουμε, ξαναπροσπαθούμε, συνομιλούμε, διαφωνούμε, συνδέουμε το νέο με όσα ήδη γνωρίζουμε. Η τεχνητή νοημοσύνη, αντίθετα, δεν έχει βίωμα, πρόθεση, παιδαγωγική ευθύνη ή κατανόηση με την ανθρώπινη έννοια. Παράγει πιθανές απαντήσεις με βάση πρότυπα που έχει αντλήσει από τεράστιους όγκους δεδομένων. Μπορεί να μιμείται πειστικά τη γλώσσα της σκέψης, χωρίς να σκέφτεται όπως σκέφτεται ένας άνθρωπος.
Αυτή η διάκριση είναι κρίσιμη για την εκπαίδευση. Αν δούμε την τεχνητή νοημοσύνη ως «εξυπνότερο μαθητή» ή ως «αυτόματο δάσκαλο», θα οργανώσουμε το σχολείο γύρω από μια παρανόηση. Αν τη δούμε ως ισχυρό, αλλά περιορισμένο υπολογιστικό εργαλείο, τότε μπορούμε να την αξιοποιήσουμε χωρίς να αλλοιώσουμε τον πυρήνα της μάθησης.
Από την υποστήριξη στη γνωσιακή εκχώρηση
Το κείμενο για τη δημόσια διοίκηση επισημαίνει ότι η τεχνητή νοημοσύνη δεν μπορεί να σώσει έναν οργανισμό όταν τα έγγραφα είναι άναρχα, διάσπαρτα, ατεκμηρίωτα και χωρίς διακυβέρνηση. Το ίδιο ισχύει και στην εκπαίδευση. Η ΤΝ δεν μπορεί να ενισχύσει τη μάθηση όταν δεν υπάρχει σαφής παιδαγωγικός σκοπός, όταν οι πηγές δεν ελέγχονται, όταν η εργασία του μαθητή γίνεται απλή ανάθεση σε μια πλατφόρμα και όταν ο εκπαιδευτικός χάνει τον έλεγχο της διαδικασίας.
Ο κίνδυνος δεν είναι μόνο η λογοκλοπή ή οι λανθασμένες απαντήσεις. Ο βαθύτερος κίνδυνος είναι η γνωσιακή εκχώρηση: ο μαθητής να παύει σταδιακά να αναλαμβάνει ο ίδιος την προσπάθεια κατανόησης. Όταν η περίληψη, η επιχειρηματολογία, η μετάφραση, η επίλυση, η διόρθωση και η παραγωγή ιδεών γίνονται κυρίως από ένα σύστημα, τότε αλλάζει ο τρόπος με τον οποίο ο μαθητής μαθαίνει. Δεν ασκείται στον κόπο της διατύπωσης, στην επιλογή επιχειρημάτων, στην αναζήτηση πηγών, στην αμφιβολία, στην επιμονή. Μαθαίνει να ζητά απάντηση, όχι να χτίζει κρίση.
Η αλλοίωση της γνωστικής λειτουργίας δεν συμβαίνει από τη μια μέρα στην άλλη. Συμβαίνει αθόρυβα, όταν η ευκολία αντικαθιστά τη μαθησιακή προσπάθεια. Όπως η διαρκής εξάρτηση από την αναζήτηση στο διαδίκτυο άλλαξε τη σχέση μας με τη μνήμη, έτσι και η διαρκής εξάρτηση από γεννήτριες απαντήσεων μπορεί να αλλάξει τη σχέση μας με την κρίση, τη συγκέντρωση και τη γλωσσική ακρίβεια.
Η παιδαγωγική απάντηση δεν είναι απαγόρευση, είναι δημοκρατικός έλεγχος
Το σχολείο δεν μπορεί να αγνοήσει την τεχνητή νοημοσύνη. Οι μαθητές ήδη τη χρησιμοποιούν. Το ερώτημα είναι με ποιους κανόνες, με ποια εργαλεία και με ποια παιδαγωγική στόχευση. Η απάντηση δεν είναι η γενική απαγόρευση, αλλά η δημόσια, ανοιχτή και παιδαγωγικά ελεγχόμενη ένταξη.
Πρώτον, χρειάζεται καθαρή διάκριση ανάμεσα στη χρήση της ΤΝ ως βοηθήματος και στη χρήση της ως υποκατάστατου της σκέψης. Ένα εργαλείο μπορεί να βοηθήσει έναν μαθητή να οργανώσει σημειώσεις, να συγκρίνει πηγές, να εντοπίσει ασάφειες σε ένα κείμενο ή να προτείνει ερωτήματα. Δεν πρέπει όμως να μετατρέπεται στον πραγματικό συγγραφέα της εργασίας, στον αόρατο λύτη των ασκήσεων ή στον τελικό κριτή της γνώσης.
Δεύτερον, η ΤΝ στην εκπαίδευση πρέπει να στηρίζεται σε ανοιχτές τεχνολογίες, ανοιχτά πρότυπα και ελεγχόμενες δημόσιες υποδομές. Δεν μπορεί η μαθησιακή διαδικασία να εξαρτάται από κλειστά εμπορικά συστήματα που συλλέγουν δεδομένα, αλλάζουν όρους χρήσης και λειτουργούν ως μαύρα κουτιά. Το δημόσιο σχολείο χρειάζεται εργαλεία που μπορούν να ελεγχθούν, να προσαρμοστούν στην ελληνική γλώσσα, να υπηρετούν το αναλυτικό πρόγραμμα και να προστατεύουν τα δεδομένα μαθητών και εκπαιδευτικών.
Τρίτον, χρειάζεται επιμόρφωση των εκπαιδευτικών. Ο εκπαιδευτικός δεν πρέπει να μείνει μόνος απέναντι σε μια τεχνολογία που αλλάζει ταχύτατα. Χρειάζεται να γνωρίζει πότε η ΤΝ βοηθά, πότε παραπλανά, πότε ενισχύει τη μαθησιακή διαδικασία και πότε την αδειάζει από περιεχόμενο. Χρειάζεται επίσης να μπορεί να σχεδιάζει δραστηριότητες όπου ο μαθητής εξηγεί τη σκέψη του, τεκμηριώνει τις επιλογές του και αξιολογεί κριτικά την απάντηση της μηχανής.
Να προστατεύσουμε τη σκέψη ως κοινό αγαθό
Η εκπαίδευση δεν υπάρχει για να παράγει γρήγορες απαντήσεις. Υπάρχει για να καλλιεργεί ανθρώπους ικανούς να σκέφτονται, να συνεργάζονται, να αμφισβητούν, να δημιουργούν και να συμμετέχουν στη δημοκρατική ζωή. Αν η τεχνητή νοημοσύνη χρησιμοποιηθεί χωρίς όρια, μπορεί να φτωχύνει τη γλώσσα, να μειώσει την αντοχή στην πνευματική δυσκολία και να κάνει τη γνώση επιφανειακή.
Γι’ αυτό η βασική αρχή πρέπει να είναι απλή: η ΤΝ στην εκπαίδευση να υπηρετεί τη μάθηση, όχι να την αντικαθιστά. Να ενισχύει τον εκπαιδευτικό, όχι να τον υποκαθιστά. Να βοηθά τον μαθητή να σκέφτεται καλύτερα, όχι να σκέφτεται λιγότερο. Και κυρίως, να σχεδιάζεται ως δημόσια παιδαγωγική υποδομή, με ανοιχτότητα, διαφάνεια, λογοδοσία και ανθρώπινη ευθύνη.
Betsy Sparrow, Jenny Liu, Daniel M. Wegner, “Google Effects on Memory: Cognitive Consequences of Having Information at Our Fingertips”: Κλασική ερευνητική εργασία για το πώς η εύκολη πρόσβαση σε εξωτερικές πηγές πληροφορίας επηρεάζει τη μνήμη και τη γνωσιακή εξάρτηση από τεχνολογικά μέσα: https://www.science.org/doi/10.1126/science.1207745.
Το Coordinate me επιστρέφει για τρίτη χρονιά ως διεθνής διαγωνισμός στο Wikidata, με στόχο την ενίσχυση και εμπλουτισμό δεδομένων που περιλαμβάνουν γεωγραφικές πληροφορίες – από μικρούς οικισμούς και φαρμακεία έως δημόσια τέχνη και φυσικά μνημεία.
Ο διαγωνισμός επικεντρώνεται στη δημιουργία και βελτίωση στοιχείων στο Wikidata που σχετίζονται με συγκεκριμένες χώρες-στόχους, ενισχύοντας έτσι την ποιότητα και την πληρότητα των ανοιχτών γεωδεδομένων.
Το Coordinate me 2026 θα πραγματοποιηθεί από τις 1 έως τις 31 Μαΐου 2026. Κατά τη διάρκειά του, συντάκτες από όλο τον κόσμο θα έχουν τη δυνατότητα να συμμετάσχουν, συμβάλλοντας ενεργά στην ενίσχυση της γνώσης που διατίθεται ελεύθερα μέσω του Wikidata.
Για τη συμμετοχή τους, οι ενδιαφερόμενοι μπορούν να ακολουθήσουν τις αναλυτικές οδηγίες που είναι διαθέσιμες στη σχετική σελίδα του εγχειρήματος.
Συνολικά, θα απονεμηθούν βραβεία αξίας 4.850 ευρώ σε διακριθέντες συμμετέχοντες, ως αναγνώριση της συνεισφοράς τους.
Ο διαγωνισμός υποστηρίζεται από το Wikimedia Community User Group Greece.
Για χρόνια, ο ανοιχτός κώδικας αντιμετωπιζόταν ως καθαρά τεχνική υπόθεση — ένα εργαλείο που επέλεγαν οι ομάδες ανάπτυξης για να επιταχύνουν τους ρυθμούς τους ή να περιορίσουν τα έξοδα αδειοδότησης. Η νέα
Στηριγμένη σε περισσότερες από 700 απαντήσεις επαγγελματιών που χρησιμοποιούν λογισμικό ανοιχτού κώδικα σε οργανισμούς κάθε μεγέθους, από δεκάδες κλάδους και κάθε γωνιά του κόσμου, η έκθεση καταγράφει μια ξεκάθαρη στροφή: ο ανοιχτός κώδικας έχει πλέον ανέλθει στην ατζέντα της ηγεσίας ως στρατηγικό ζήτημα.
Εύρημα 1ο: Ο Φόβος Εξάρτησης από Προμηθευτές Ωθεί την Υιοθέτηση
Η αποφυγή εξάρτησης από έναν μεμονωμένο προμηθευτή αναδείχθηκε σε έναν από τους κυριότερους λόγους στροφής στον ανοιχτό κώδικα, καθώς το ανέφερε το 55% των ερωτηθέντων — αύξηση 68% σε σχέση με πέρυσι.
Το φαινόμενο είναι ακόμα πιο έντονο στην Ευρώπη: το 63% των οργανισμών στην ΕΕ και στο Ηνωμένο Βασίλειο θέτουν την αποφυγή εξάρτησης από προμηθευτές ως πρωταρχικό κίνητρο, έναντι 51% στη Βόρεια Αμερική.
Πίσω από αυτά τα νούμερα κρύβεται μια βαθύτερη λογική: ο ανοιχτός κώδικας συνδέεται πλέον με την ψηφιακή κυριαρχία και τον μακροπρόθεσμο έλεγχο των τεχνολογικών επιλογών, και όχι απλώς με άμεση εξοικονόμηση κόστους. Σε ένα ασταθές οικονομικό και κανονιστικό περιβάλλον, οι οργανισμοί επιδιώκουν να διατηρούν το χειριστήριο στα χέρια τους.
Εύρημα 2ο: Η Συντήρηση Ρουφάει τον Χρόνο που Θα Έπρεπε να Πηγαίνει στην Καινοτομία
Στις μεγαλύτερες επιχειρήσεις (άνω των 5.000 εργαζομένων), το 60% των ερωτηθέντων δηλώνει ότι αφιερώνει τουλάχιστον τον μισό χρόνο εργασίας του σε συντήρηση, επίλυση προβλημάτων παραγωγής και διόρθωση σφαλμάτων, αντί για ανάπτυξη νέων λειτουργιών.
Σε ορισμένα τεχνολογικά οικοσυστήματα η ισορροπία είναι ακόμα πιο ανησυχητική. Το 31% των επιχειρησιακών ομάδων Java αφιερώνει μόλις το 10–25% του χρόνου τους σε νέες λειτουργίες — γεγονός που έχει άμεσο αντίκτυπο στα χρονοδιαγράμματα παράδοσης και στο ηθικό των προγραμματιστών.
Ένας πιθανός ένοχος για τις ομάδες Java είναι ο επιταχυνόμενος εξαμηνιαίος κύκλος κυκλοφορίας του JDK, που επιβάλλει συνεχείς αναβαθμίσεις και αφήνει ελάχιστα περιθώρια για ουσιαστική ανάπτυξη.
Εύρημα 3ο: Ασφάλεια και Ευπάθειες Παραμένουν Αχίλλειος Πτέρνα
Παρά την ολοένα μεγαλύτερη ωριμότητα στη χρήση ανοιχτού κώδικα, η ενημέρωση ασφαλείας και η διαχείριση ευπαθειών παραμένουν η πιο επίμονη πρόκληση, ανεξάρτητα από το μέγεθος του οργανισμού. Τα στοιχεία είναι αποκαλυπτικά:
Ένας στους πέντε οργανισμούς δηλώνει ότι δεν διαθέτει καμία τυπική διαδικασία για την αντιμετώπιση γνωστών κενών ασφαλείας (CVEs).
Τέσσερις στις δέκα μεγάλες επιχειρήσεις δυσκολεύονται να τηρήσουν τους εσωτερικούς χρόνους αποκατάστασης ευπαθειών που οι ίδιες έχουν ορίσει.
Περισσότεροι από τους μισούς οργανισμούς που απέτυχαν σε έλεγχο συμμόρφωσης το περασμένο έτος χρησιμοποιούσαν λογισμικό ανοιχτού κώδικα που έχει βγει εκτός υποστήριξης.
Συμπέρασμα: Ο Ανοιχτός Κώδικας ως Στρατηγικό Κεφάλαιο
Λιγότεροι από 2 στους 100 οργανισμούς ανέφεραν μείωση στη χρήση ανοιχτού κώδικα κατά το περασμένο έτος. Για το υπόλοιπο 98%, το ερώτημα δεν είναι πλέον αν θα τον χρησιμοποιήσουν, αλλά πώς θα τον διαχειριστούν με σύνεση — πώς θα τον ασφαλίσουν, πώς θα τον συντηρήσουν σε επιχειρησιακή κλίμακα, χωρίς να θυσιαστεί η καινοτομία ή ο έλεγχος.
Ο ανοιχτός κώδικας δεν είναι πια απλώς μια τεχνολογική προτίμηση — είναι ταυτόχρονα στρατηγικό κεφάλαιο και στρατηγική ευθύνη. Οι οργανισμοί που θα το αντιληφθούν έγκαιρα, επενδύοντας στη διακυβέρνηση, στην ασφάλεια και στην κατάρτιση των ομάδων τους, θα διαθέτουν σαφές ανταγωνιστικό πλεονέκτημα στα χρόνια που ακολουθούν.
Τα τελευταία χρόνια, τα σκάνδαλα παρακολούθησης μέσω spyware έχουν προκαλέσει έντονες αντιδράσεις σε ολόκληρη την Ευρώπη, αποκαλύπτοντας σοβαρές απειλές για τη δημοκρατία, τα ανθρώπινα δικαιώματα και την ιδιωτικότητα των πολιτών. Ωστόσο, πέρα από τα ίδια τα σκάνδαλα, αναδύεται ένα ακόμη πιο ανησυχητικό ζήτημα: ο ρόλος της Ευρωπαϊκής Ένωσης στη χρηματοδότηση της ίδιας της βιομηχανίας που καθιστά αυτές τις παραβιάσεις δυνατές.
Η περίπτωση της Ελλάδας αποτελεί χαρακτηριστικό παράδειγμα. Το σκάνδαλο «Predatorgate» αποκάλυψε τη χρήση κατασκοπευτικού λογισμικού για την παρακολούθηση δημοσιογράφων, πολιτικών και επιχειρηματιών. Το 2026, τέσσερα άτομα καταδικάστηκαν σε φυλάκιση, σηματοδοτώντας μία από τις πρώτες περιπτώσεις όπου στελέχη εταιρείας spyware αντιμετωπίζουν ποινικές ευθύνες. Παρά τη σημασία αυτής της εξέλιξης, το ερώτημα που τίθεται είναι βαθύτερο: πώς είναι δυνατόν η ίδια η ΕΕ να συμβάλλει, άμεσα ή έμμεσα, στη χρηματοδότηση τέτοιων τεχνολογιών;
Έρευνες όπως η Follow The Money’s investigation έχουν δείξει ότι σημαντικά ποσά ευρωπαϊκών κονδυλίων —μέσω προγραμμάτων όπως το European Defence Fund και το Horizon, αλλά και μέσω τραπεζικών και επενδυτικών μηχανισμών— έχουν καταλήξει σε εταιρείες που αναπτύσσουν spyware. Ακόμη πιο ανησυχητικό είναι το γεγονός ότι αυτά τα κεφάλαια προέρχονται από χρήματα φορολογουμένων, τα οποία τελικά χρησιμοποιούνται για δραστηριότητες που υπονομεύουν τα δικαιώματα των ίδιων των Ευρωπαίων πολιτών.
Η έλλειψη διαφάνειας αποτελεί βασικό πρόβλημα. Θεσμοί όπως η Ευρωπαϊκή Τράπεζα Επενδύσεων και το Ευρωπαϊκό Ταμείο Επενδύσεων φαίνεται να αδυνατούν ή να αρνούνται να παρέχουν σαφείς πληροφορίες σχετικά με το πού καταλήγουν τα χρήματα και πώς χρησιμοποιούνται. Αυτό δημιουργεί ένα σοβαρό δημοκρατικό έλλειμμα και καθιστά σχεδόν αδύνατο τον ουσιαστικό έλεγχο από το Ευρωπαϊκό Κοινοβούλιο και την κοινωνία.
Παράλληλα, η στάση της Ευρωπαϊκής Επιτροπής εγείρει ερωτήματα. Αν και δηλώνει ότι θα λάβει μέτρα σε περιπτώσεις παραβίασης ανθρωπίνων δικαιωμάτων, στην πράξη δεν φαίνεται να έχει κινηθεί αποφασιστικά, ακόμη και όταν υπάρχουν σαφή στοιχεία για καταχρήσεις.
Η κατάσταση αυτή οδηγεί στο συμπέρασμα ότι η ΕΕ δεν είναι απλώς παθητικός παρατηρητής, αλλά ενδέχεται να λειτουργεί ως ενεργός ενισχυτής της βιομηχανίας spyware. Οι συνέπειες είναι σοβαρές: περιορισμός της ελευθερίας της έκφρασης, διάβρωση της εμπιστοσύνης στους θεσμούς και υπονόμευση της δημοκρατικής λειτουργίας.
Οι προτάσεις για την αντιμετώπιση του προβλήματος είναι σαφείς. Πρώτον, απαιτείται άμεση διακοπή κάθε χρηματοδότησης προς εταιρείες spyware, είτε μέσω επιχορηγήσεων είτε μέσω επενδύσεων. Δεύτερον, πρέπει να ενισχυθούν οι μηχανισμοί ελέγχου, διαφάνειας και λογοδοσίας στη διαχείριση των ευρωπαϊκών κονδυλίων. Τέλος, προτείνεται η καθολική απαγόρευση της χρήσης και ανάπτυξης spyware στην Ευρωπαϊκή Ένωση.
Σε μια εποχή όπου η ψηφιακή επικοινωνία αποτελεί βασικό πυλώνα της κοινωνικής και πολιτικής ζωής, η προστασία της ιδιωτικότητας και των θεμελιωδών δικαιωμάτων δεν μπορεί να είναι διαπραγματεύσιμη. Η Ευρώπη καλείται να επιλέξει: θα συνεχίσει να χρηματοδοτεί μια επικίνδυνη βιομηχανία ή θα αναλάβει δράση για την προστασία των πολιτών της;
Το Fedora Project ανακοίνωσε επίσημα την κυκλοφορία του Fedora 44 στις 28 Απριλίου 2026, επιβεβαιώνοντας για άλλη μια φορά τη φήμη του ως η διανομή που οδηγεί τις εξελίξεις στο οικοσύστημα του Linux. Ως το “πεδίο δοκιμών” για τεχνολογίες που αργότερα ενσωματώνονται στο Red Hat Enterprise Linux (RHEL), το Fedora 44 δεν είναι απλώς μια ενημέρωση, αλλά μια ματιά στο μέλλον της πληροφορικής.
Η νέα έκδοση εστιάζει στην παροχή των πιο σύγχρονων εργαλείων για καθημερινούς χρήστες, gamers και προγραμματιστές, προσφέροντας μια σταθερή αλλά ταυτόχρονα πρωτοποριακή εμπειρία. Με την υποστήριξη του Linux kernel 6.19 (και με το kernel 7.0 να αναμένεται σύντομα στα αποθετήρια), το Fedora 44 είναι έτοιμο να αξιοποιήσει στο έπακρο το σύγχρονο hardware.
Fedora 44 Workstation: Η απόλυτη εμπειρία Desktop με GNOME 50
Η ναυαρχίδα της διανομής, το Fedora 44 Workstation, συνοδεύεται από το πολυαναμενόμενο περιβάλλον εργασίας GNOME 50. Η νέα έκδοση του GNOME φέρνει μια πληθώρα βελτιώσεων που εστιάζουν στην προσβασιμότητα, τη διαχείριση χρωμάτων και την απομακρυσμένη επιφάνεια εργασίας.
1. Ψηφιακή ευεξία και Γονικός έλεγχος
Μια από τις πιο σημαντικές προσθήκες στο GNOME 50 είναι η πρωτοβουλία Digital Wellbeing. Πλέον, οι χρήστες μπορούν να βρουν ενσωματωμένα Parental Controls απευθείας μέσα από τις Ρυθμίσεις του συστήματος. Αυτό επιτρέπει στους γονείς να ορίζουν:
Όρια χρόνου χρήσης της οθόνης.
Συγκεκριμένες ώρες κατάκλισης για τον περιορισμό της χρήσης το βράδυ.
2. Βελτιωμένες εφαρμογές συστήματος
Πολλές από τις προεγκατεστημένες εφαρμογές έχουν δεχθεί σημαντικές αναβαθμίσεις για να γίνουν πιο γρήγορες και λειτουργικές:
Διαχειριστής Αρχείων (Files): Πιο ομαλή πλοήγηση και βελτιωμένη αναζήτηση.
Ημερολόγιο (Calendar): Νέες δυνατότητες οργάνωσης και καθαρότερο περιβάλλον.
Προβολή Εγγράφων (Document Viewer): Ταχύτερη φόρτωση αρχείων PDF και βελτιωμένη απόδοση.
KDE Plasma 6.6: Ολοκληρωμένη εμπειρία από την πρώτη εκκίνηση
Για τους λάτρεις του KDE, το Fedora 44 προσφέρει το KDE Plasma 6.6, το οποίο φέρνει μια πιο συνεκτική και ολοκληρωμένη εμπειρία χρήσης.
Plasma Login Manager και Plasma Setup
Δύο μεγάλες αλλαγές που θα παρατηρήσουν αμέσως οι χρήστες των KDE variants (όπως το KDE Plasma Desktop Edition και το Kinoite) είναι:
Plasma Login Manager: Ο νέος προεπιλεγμένος διαχειριστής σύνδεσης προσφέρει μια πιο ομοιόμορφη εμφάνιση που ταιριάζει με το υπόλοιπο περιβάλλον εργασίας.
Plasma Setup: Μια νέα εφαρμογή που τρέχει μετά την εγκατάσταση και επιτρέπει στους χρήστες να ρυθμίσουν το σύστημά τους εύκολα και γρήγορα. Αυτό το εργαλείο καθιστά το Fedora KDE ιδανικό ακόμα και για εγκαταστάσεις σε υπολογιστές φίλων ή συγγενών που δεν έχουν μεγάλη εμπειρία με το Linux.
Σημείωση για την αναβάθμιση: Οι χρήστες που αναβαθμίζουν από παλαιότερες εκδόσεις του KDE θα διατηρήσουν τον παλιό SDDM login manager από προεπιλογή, αλλά μπορούν να μεταβούν στο νέο Plasma Login Manager χειροκίνητα μέσω τερματικού
Linux Gaming: Το Fedora 44 αλλάζει τους κανόνες του παιχνιδιού
Αν είστε gamer, το Fedora 44 είναι ίσως η σημαντικότερη αναβάθμιση που έχετε δει τα τελευταία χρόνια. Η διανομή κάνει ένα τεράστιο βήμα μπροστά για να προσφέρει επιδόσεις που πλησιάζουν (ή και ξεπερνούν σε κάποιες περιπτώσεις) την εμπειρία των Windows.
1. Ενεργοποίηση του NTSYNC: Ταχύτητα και Συμβατότητα
Η μεγαλύτερη είδηση για τους παίκτες είναι η ενεργοποίηση του kernel module NTSYNC από προεπιλογή για συγκεκριμένα πακέτα. Το NTSYNC είναι ένα module του πυρήνα (διαθέσιμο από την έκδοση 6.14 και μετά) που βελτιώνει θεαματικά τον τρόπο με τον οποίο οι εφαρμογές Windows επικοινωνούν με το σύστημα μέσω του Wine και του Proton.
Τι σημαίνει αυτό για εσάς; Καλύτερες επιδόσεις και μεγαλύτερη συμβατότητα σε παιχνίδια που τρέχετε μέσω Steam ή Wine.
Αυτόματη ρύθμιση: Το Fedora φροντίζει ώστε, αν εγκαταστήσετε πακέτα που το προτείνουν (όπως το Steam από το RPM Fusion), το NTSYNC να διαμορφώνεται αυτόματα κατά την εκκίνηση, χωρίς να χρειάζεται να σκαλίζετε το τερματικό.
Tip: Για όσους θέλουν να το ενεργοποιήσουν χειροκίνητα, το πακέτο ntsync-autoload είναι ο σύμμαχός σας.
2. Το Fedora Games Lab μετακομίζει στο KDE Plasma
Το Fedora Games Lab, η ειδική έκδοση (Spin) που είναι φορτωμένη με παιχνίδια και εργαλεία ανάπτυξης, ανανεώθηκε πλήρως. Η σημαντικότερη αλλαγή είναι η μετάβαση από το περιβάλλον Xfce στο KDE Plasma.
Μοντέρνα εμπειρία: Η χρήση του KDE Plasma προσφέρει μια πιο σύγχρονη και πλούσια εμπειρία χρήσης, ιδανική για το σημερινό gaming hardware.
Νέα εργαλεία: Περιλαμβάνει ένα εκσυγχρονισμένο σετ παιχνιδιών και εργαλείων ανάπτυξης (game development tools).
Προσοχή στην αναβάθμιση: Αν χρησιμοποιείτε την παλιά έκδοση με Xfce, δεν θα αναβαθμιστείτε αυτόματα στο KDE. Θα χρειαστείτε μια φρέσκια εγκατάσταση ή χειροκίνητη παρέμβαση.
Anaconda: Ένας εξυπνότερος εγκαταστάτης
Ο εγκαταστάτης του Fedora, ο γνωστός Anaconda, έγινε πιο “συμμαζεμένος” και αποδοτικός στην έκδοση 44. Η ομάδα ανάπτυξης αποφάσισε να ακολουθήσει τη λογική “λιγότερα είναι περισσότερα” όσον αφορά τη διαχείριση του δικτύου.
Τέλος στα περιττά προφίλ δικτύου
Μέχρι τώρα, το Anaconda δημιουργούσε προεπιλεγμένα προφίλ για όλες τις συσκευές δικτύου που εντόπιζε, ακόμα και αν δεν τις χρησιμοποιούσατε. Στο Fedora 44:
Δημιουργούνται προφίλ μόνο για τις συσκευές που ρυθμίζετε εσείς κατά την εγκατάσταση (είτε μέσω του UI, είτε μέσω kickstart).
Αυτό απλοποιεί τη διαμόρφωση του δικτύου μετά την εγκατάσταση, ειδικά για χρήστες που θέλουν να κάνουν εξειδικευμένες ρυθμίσεις αργότερα.
Budgie 10.10 και MiracleWM: Νέες επιλογές για το Desktop
Το Fedora συνεχίζει να υποστηρίζει την πολυφωνία, προσφέροντας ενημερωμένα “Spins” για κάθε γούστο:
Budgie 10.10: Η νέα έκδοση του Budgie εστιάζει πλέον στο Wayland, προσφέροντας μια εξαιρετικά ομαλή εμπειρία χρήσης. Αν και είναι Wayland-centric, μην ανησυχείτε: οι X11 εφαρμογές εξακολουθούν να υποστηρίζονται κανονικά.
MiracleWM: Το Fedora MiracleWM spin αντικατέστησε το προεπιλεγμένο nwg-shell με το DankMaterialShell (βασισμένο στο QuickShell). Το αποτέλεσμα; Ένα περιβάλλον πιο γρήγορο, πιο σταθερό και με περισσότερες δυνατότητες.
Σημαντική ειδοποίηση για χρήστες AppImages (Atomic Desktops)
Αν χρησιμοποιείτε τις “Atomic” εκδόσεις του Fedora (όπως το Silverblue ή το Kinoite), προσέξτε μια σημαντική αλλαγή: οι βιβλιοθήκες FUSE 2 έχουν αφαιρεθεί.
Πολλά παλαιότερα AppImages εξαρτώνται από αυτές τις βιβλιοθήκες και ενδέχεται να σταματήσουν να λειτουργούν.
Η λύση: Προτιμήστε την έκδοση Flatpak των εφαρμογών σας αν υπάρχει, ή ζητήστε από τους δημιουργούς να αναβαθμίσουν το AppImage στο νεότερο runtime.
Για τους Διαχειριστές Συστημάτων: Έλεγχος και Ευελιξία
Αν το Fedora Workstation είναι το πρόσωπο της διανομής, τα εργαλεία συστήματος είναι οι μυς του. Οι αλλαγές εδώ στοχεύουν στην απλοποίηση πολύπλοκων εργασιών.
1. Nix Package Manager: Ένα σύμπαν 100.000 πακέτων
Για πρώτη φορά, το Nix package tool είναι επίσημα διαθέσιμο στο Fedora. Πρόκειται για έναν cross-platform διαχειριστή πακέτων που χρησιμοποιεί μια δηλωτική λειτουργική γλώσσα προγραμματισμού.
Πρόσβαση σε τεράστιο αποθετήριο: Οι χρήστες αποκτούν πρόσβαση στο οικοσύστημα nixpkgs, το οποίο διαθέτει πάνω από 100.000 πακέτα.
Ασφάλεια και Διαχωρισμός: Τα πακέτα που εγκαθίστανται μέσω Nix δεν γίνονται μέρος της διανομής Fedora, κάτι που σημαίνει ότι μπορείτε να πειραματιστείτε χωρίς να φοβάστε ότι θα «σπάσετε» το κεντρικό σύστημα.
Ευελιξία: Υποστηρίζονται τόσο η λειτουργία πολλαπλών χρηστών (multi-user) όσο και η λειτουργία ενός χρήστη (single-user).
2. Stratis 3.9.0: Η επανάσταση στην αποθήκευση
Το εργαλείο διαχείρισης αποθήκευσης Stratis αναβαθμίστηκε στην έκδοση 3.9.0, εισάγοντας δύο κρίσιμα χαρακτηριστικά:
Online Κρυπτογράφηση και Επανακρυπτογράφηση: Πλέον είναι δυνατή η κρυπτογράφηση, η αποκρυπτογράφηση και η αλλαγή κλειδιού (reencryption) ενός Stratis pool ενώ αυτό είναι σε χρήση. Προηγουμένως, η απόφαση για κρυπτογράφηση έπρεπε να ληφθεί κατά τη δημιουργία του pool.
Εκκίνηση χωρίς Cache: Σε περίπτωση που οι συσκευές προσωρινής αποθήκευσης είναι κατεστραμμένες ή λείπουν, μπορείτε να εκκινήσετε το pool χωρίς αυτές, εξασφαλίζοντας την πρόσβαση στα δεδομένα σας.
3. MariaDB 11.8: Έτοιμο για την εποχή της Τεχνητής Νοημοσύνης
Η προεπιλεγμένη έκδοση της βάσης δεδομένων MariaDB είναι πλέον η 11.8. Οι βελτιώσεις είναι εντυπωσιακές:
Υποστήριξη Vector: Προστέθηκε υποστήριξη για vector δεδομένα, κάτι απαραίτητο για εφαρμογές μηχανικής μάθησης (Machine Learning).
Unicode παντού: Χρησιμοποιείται πλέον το σύνολο χαρακτήρων utf8mb4 από προεπιλογή, εξασφαλίζοντας πλήρη υποστήριξη Unicode.
Τέλος στο πρόβλημα του 2038: Το ανώτατο όριο του τύπου δεδομένων TIMESTAMP αυξήθηκε από το 2038 στο 2106, διατηρώντας την ίδια κατανάλωση αποθηκευτικού χώρου (4 bytes).
Ταχύτητα: Τα εργαλεία mariadb-dump και mariadb-import υποστηρίζουν πλέον εγγενώς παράλληλες λειτουργίες για ταχύτερη διαχείριση μεγάλων βάσεων.
Για τους Προγραμματιστές: Τα καλύτερα εργαλεία της αγοράς
Το Fedora 44 επιβεβαιώνει τη θέση του ως η κορυφαία πλατφόρμα ανάπτυξης λογισμικού, προσφέροντας τις πιο πρόσφατες εκδόσεις γλωσσών και εργαλείων.
1. Ruby 4.0
Με τη μετάβαση από τη Ruby 3.4 στη Ruby 4.0, το Fedora γίνεται η ανώτερη πλατφόρμα για Ruby developers.
Απόδοση: Πολλές νέες δυνατότητες και βελτιώσεις για τις αυξανόμενες απαιτήσεις των σύγχρονων εφαρμογών.
Βελτιστοποιημένη εγκατάσταση: Το πακέτο ruby-build διαχωρίστηκε σε υποπακέτα, με αποτέλεσμα μια σημαντικά ταχύτερη και μικρότερη σε όγκο διαδικασία εγκατάστασης.
2. Java
Σημαντική αλλαγή για τους Java developers: το Fedora 44 αφαιρεί την έκδοση 21 LTS και καθιστά την JDK 25 LTS ως την προεπιλεγμένη unversioned έκδοση.
Αυτοματισμός: Οι εφαρμογές που δεν έχουν ρυθμιστεί χειροκίνητα θα μεταβούν αυτόματα στην έκδοση 25.
Συμβατότητα: Αν απαιτούνται παλαιότερες εκδόσεις, προτείνεται η χρήση των RPM από το project Eclipse Adoptium (Temurin), τα οποία ενσωματώνονται άψογα στο Fedora.
3. Σύγχρονο Toolchain και βιβλιοθήκες
Οι προγραμματιστές έχουν στη διάθεσή τους τα πιο πρόσφατα εργαλεία:
Μεταγλωττιστές: GCC 16.1, LLVM 22 και Go 1.26.
Frameworks & Εργαλεία: Django 6.0, PHP 8.5, Ansible 13 και Helm 4 (με παράλληλη υποστήριξη για το Helm 3).
Βιβλιοθήκες: Boost 1.90 και TagLib 2 (προσοχή: η έκδοση 2 φέρνει αλλαγές στο ABI/API).
4. NodeJS και διαχείριση εκδόσεων
Εισάγονται τα swappable πακέτα -bin για τη διαχείριση των symlinks του NodeJS. Πλέον, μπορείτε να αλλάζετε την έκδοση του Node (π.χ. μεταξύ v20, v22 και v24) εύκολα με μια εντολή dnf swap, διασφαλίζοντας ότι οι εντολές node και npm δείχνουν στην έκδοση που επιθυμείτε.
Δομικές αλλαγές και ασφάλεια
Αναπαραγώγιμα Πακέτα: Το Fedora 44 είναι η πρώτη έκδοση όπου όλα τα πακέτα αποστέλλονται ως αναπαραγώγιμα, ενισχύοντας την εμπιστοσύνη στην ακεραιότητα του λογισμικού.
Btrfs subvolume για το Cloud: Οι εικόνες Fedora Cloud δεν χρησιμοποιούν πλέον ξεχωριστό /boot partition, αλλά ένα Btrfs subvolume. Αυτό επιτρέπει καλύτερη αξιοποίηση του χώρου και μικρότερο μέγεθος εικόνων.
PackageKit + DNF5: Το PackageKit (που τροφοδοτεί εφαρμογές όπως το GNOME Software και το Plasma Discover) χρησιμοποιεί πλέον το DNF5, προσφέροντας μια πιο ενιαία και αξιόπιστη εμπειρία διαχείρισης λογισμικού.
OpenSSL: Βελτιώθηκε ο χρόνος φόρτωσης του OpenSSL μέσω της υποστήριξης directory-hash για τα πιστοποιητικά (ca-certificates).
Πώς να αναβαθμίσετε στο Fedora 44
Η αναβάθμιση στο Fedora 44 είναι μια απλή διαδικασία, αλλά όπως σε κάθε μεγάλη αλλαγή λειτουργικού, η προετοιμασία είναι το κλειδί.
1. Μέσω Γραφικού Περιβάλλοντος (GUI)
Για τους περισσότερους χρήστες, η αναβάθμιση μπορεί να γίνει εύκολα μέσω του GNOME Software ή του Plasma Discover. Θα λάβετε μια ειδοποίηση ότι η νέα έκδοση είναι διαθέσιμη και το μόνο που έχετε να κάνετε είναι να ακολουθήσετε τις οδηγίες στην οθόνη.
2. Μέσω Τερματικού (CLI)
Οι πιο προχωρημένοι χρήστες προτιμούν συχνά τη σιγουριά του τερματικού. Η διαδικασία περιλαμβάνει τις εξής εντολές:
sudo dnf upgrade –refresh (για να έχετε το τρέχον σύστημα πλήρως ενημερωμένο).
sudo dnf install dnf-plugin-system-upgrade (αν δεν είναι ήδη εγκατεστημένο).
sudo dnf system-upgrade download –releasever=44.
sudo dnf system-upgrade reboot.
Επίλυση Προβλημάτων (Troubleshooting): Τι να προσέξετε
Παρά τη σταθερότητα της διανομής, ορισμένοι χρήστες ενδέχεται να αντιμετωπίσουν συγκεκριμένα ζητήματα κατά τη μετάβαση. Ακολουθούν οι λύσεις στα πιο συνηθισμένα “αγκάθια”:
1. Η σύγκρουση TLP και tuned-ppd
Αν χρησιμοποιείτε το εργαλείο TLP για τη διαχείριση της μπαταρίας στο laptop σας, η αναβάθμιση ενδέχεται να αποτύχει. Αυτό συμβαίνει γιατί το Fedora 44 εισάγει το tuned-ppd ως προεπιλογή, και τα δύο πακέτα συγκρούονται επειδή προσπαθούν να διαχειριστούν τα ίδια αρχεία D-Bus.
Λύση Α (Κρατήστε το TLP): Χρησιμοποιήστε την εντολή αναβάθμισης με εξαίρεση: sudo dnf system-upgrade download –releasever=44 –ex=tuned-ppd.
Λύση Β (Μετάβαση στο νέο προεπιλεγμένο): Απεγκαταστήστε το TLP πριν την αναβάθμιση (sudo dnf remove tlp) και αφήστε το σύστημα να εγκαταστήσει το tuned-ppd.
2. Θέματα με NVIDIA Drivers
Ορισμένοι χρήστες ανέφεραν ότι οι οδηγοί (drivers) της NVIDIA ενδέχεται να παρουσιάσουν προβλήματα μετά την ενημέρωση.
Λύση: Προτείνεται η πλήρης απεγκατάσταση των παλαιών οδηγών και η εκ νέου εγκατάσταση της έκδοσης 580 (ή νεότερης) μέσω του αποθετηρίου RPM Fusion.
3. Προβλήματα δικτύου μετά την αναβάθμιση
Σε σπάνιες περιπτώσεις, μετά την αναβάθμιση οι εφαρμογές μπορεί να μην έχουν πρόσβαση στο διαδίκτυο παρόλο που η κάρτα δικτύου φαίνεται ενεργή.
Λύση: Ένας πλήρης επανακαθορισμός των SELinux contexts με την εντολή sudo restorecon -Rv / συνήθως επιλύει το πρόβλημα.
Υποστήριξη Hardware και Αρχιτεκτονικές
Το Fedora 44 συνεχίζει να επεκτείνει τα όρια του hardware:
ARM & Snapdragon: Βελτιώθηκε σημαντικά η υποστήριξη για Snapdragon WoA (Windows on ARM) laptops μέσω της αυτόματης επιλογής DTB για συστήματα AArch64 EFI.
Τέλος στα 32-bit QEMU: Σταματά επίσημα η υποστήριξη για 32-bit (i686) builds του QEMU, ακολουθώντας τις εξελίξεις στο upstream project.
Κατεβάστε το Fedora 44 σήμερα!
Είστε έτοιμοι να δοκιμάσετε τη νέα έκδοση; Επιλέξτε την έκδοση που σας ταιριάζει:
Η Ευρωπαϊκή Επιτροπή, μέσω του Public Sector Tech Watch (PSTW), άνοιξε επίσημα τις υποβολές για το Best Cases Award 2026 — ένα διαγωνισμό που αναδεικνύει τις πιο εμπνευσμένες χρήσεις αναδυόμενων τεχνολογιών από δημόσιους φορείς σε ολόκληρη την Ευρώπη.
Δημόσιες διοικήσεις σε κάθε επίπεδο — από κεντρική κυβέρνηση έως τοπική αυτοδιοίκηση — καλούνται να μοιραστούν πώς χρησιμοποιούν τεχνολογίες αιχμής για να βελτιώσουν τις υπηρεσίες τους, να ενισχύσουν τη λειτουργία τους και να υποστηρίξουν την αποτελεσματικότερη χάραξη πολιτικής.
Τι είναι το Public Sector Tech Watch
Το Public Sector Tech Watch αποτελεί μια πρωτοβουλία του Interoperable Europe Portal της Ευρωπαϊκής Επιτροπής, με στόχο την παρακολούθηση και ανάδειξη της τεχνολογικής καινοτομίας στον δημόσιο τομέα. Το ετήσιο Best Cases Award είναι το κορυφαίο διακριτικό της πρωτοβουλίας, επιβραβεύοντας έργα που μετατρέπουν την καινοτομία σε πραγματικά αποτελέσματα για πολίτες και επιχειρήσεις.
Τι έδειξε η έκδοση του 2025
Η περσινή διοργάνωση έφερε 57 υποβολές από ολόκληρη την Ευρώπη, αναδεικνύοντας τη ραγδαία υιοθέτηση ψηφιακής καινοτομίας στις δημόσιες διοικήσεις. Δύο έργα αναδείχτηκαν νικητές:
Diia.AI — Ουκρανία: Ο πρώτος εθνικός AI agent για κυβερνητικές υπηρεσίες παγκοσμίως. Αναπτύχθηκε από το Υπουργείο Ψηφιακού Μετασχηματισμού της Ουκρανίας και επιτρέπει στους πολίτες να αλληλεπιδρούν με το κράτος μέσω ΤΝ — όχι απλώς να λαμβάνουν πληροφορίες, αλλά να ολοκληρώνουν πραγματικές συναλλαγές.
WienKI — Βιέννη: Μια ολιστική πλατφόρμα ΤΝ που εκσυγχρονίζει τη δημόσια διοίκηση της αυστριακής πρωτεύουσας, με εφαρμογές σε πολλαπλούς τομείς δημοτικών υπηρεσιών.
Επιπλέον, δύο τιμητικές μνείες απονεμήθηκαν: στην Καταλονία για ένα σύστημα γενετικής ΤΝ που επιταχύνει τη σύνταξη τεχνικών εκθέσεων για περιβαλλοντικές αδειοδοτήσεις, και στη Γερμανία για ένα εργαλείο ΤΝ που εντοπίζει παράνομο εμπόριο προστατευόμενων ειδών στο διαδίκτυο.
Τι αναζητά το βραβείο για το 2026
Οι υποβολές μπορούν να αφορούν:
Βελτίωση υπηρεσιών προς πολίτες ή επιχειρήσεις
Εκσυγχρονισμό εσωτερικών διαδικασιών της διοίκησης
Υποστήριξη σχεδιασμού και αξιολόγησης πολιτικών
Γίνονται δεκτά έργα σε κάθε στάδιο υλοποίησης — ακόμα και πιλοτικά ή έργα σε αρχικό στάδιο ανάπτυξης. Οι τεχνολογίες που μπορούν να καλυφθούν περιλαμβάνουν, μεταξύ άλλων, γενετική ΤΝ, blockchain, ψηφιακούς δίδυμους και κάθε άλλη αναδυόμενη τεχνολογία με εφαρμογή στον δημόσιο τομέα.
Ποιοι μπορούν να συμμετάσχουν
Η πρόσκληση απευθύνεται σε δημόσιες διοικήσεις όλων των επιπέδων σε ολόκληρη την Ευρώπη. Το υποβάλλον φορέα πρέπει να είναι δημόσια αρχή, ωστόσο τα έργα μπορούν να έχουν αναπτυχθεί και σε συνεργασία με εξωτερικούς φορείς ή εταιρείες.
Οι νικητές του 2026 θα ανακοινωθούν κατά τη διάρκεια τελετής απονομής στο SEMIC Conference στο Δουβλίνο τον Νοέμβριο του 2026. Πέραν της αναγνώρισης, οι βραβευμένοι οργανισμοί θα προσκληθούν να παρουσιάσουν τις λύσεις τους στη διεθνή κοινότητα και θα λάβουν ένα επαγγελματικά παραγόμενο βίντεο που θα αναδεικνύει το έργο και τα αποτελέσματά τους.
Επιπλέον, όλες οι υποβολές θα ενταχθούν στον PSTW Cases Viewer, μια διαδικτυακή βάση καλών πρακτικών που επιτρέπει σε άλλες χώρες και διοικήσεις να εμπνευστούν και να αξιοποιήσουν επιτυχημένες προσεγγίσεις.
Γιατί να συμμετάσχει μια ελληνική δημόσια αρχή
Η Ελλάδα βρίσκεται σε φάση ψηφιακής επιτάχυνσης. Έργα που υλοποιούνται στο πλαίσιο του GR digiGOV-innoHUB, της ΓΓΠΣ και άλλων φορέων αποτελούν ακριβώς τον τύπο καινοτομίας που το PSTW αναζητά. Η συμμετοχή σε ένα βραβείο ευρωπαϊκής εμβέλειας προσφέρει ορατότητα, αναγνώριση και τη δυνατότητα ένταξης σε ένα διεθνές δίκτυο γνώσης και καλών πρακτικών.
Κυκλοφόρησε η νέα έκδοση, 44, της διανομής Fedora! Μπορείτε να την κατεβάσετε από το επίσημο site, ενώ για περισσότερες λεπτομέρειες μπορείτε να ρίξετε μια ματιά και στα Release Notes και στην επίσημη ανακοίνωση. Διατίθεται σε εκδόσεις για:
Οι εκδηλώσεις δεν σταματούν καθώς αυτήν την εβδομάδα πραγματοποιούνται εκδηλώσεις στην Ελλάδα και στο εξωτερικό για τις ανοιχτές τεχνολογίες και την καινοτομία! Ο Οργανισμός Ανοιχτών Τεχνολογιών (ΕΕΛΛΑΚ) σας προτείνει να τις παρακολουθήσετε και να τις διαδώσετε. Μπορείτε επίσης να δείτε περισσότερες εκδηλώσεις για τις επόμενες εβδομάδες ή να καταχωρίσετε τη δική σας εκδήλωση στο: https://ellak.gr/events.
Απομένουν μόλις 12 χρόνια προτού ένα θεμελιώδες όριο στη χρονομέτρηση απειλήσει να διαταράξει απροετοίμαστα υπολογιστικά συστήματα. Γνωστό ως το πρόβλημα του έτους 2038 — ή Y2K38, το Unix Y2K bug, ή Epochalypse — αυτό το ελάττωμα είναι πολύ πιο συνηθισμένο στη σύγχρονη υποδομή από ό,τι αντιλαμβάνονται οι περισσότεροι οργανισμοί.
Στις 03:14:07 UTC της 19ης Ιανουαρίου 2038, η Unix Epoch θα υπερβεί τη μέγιστη τιμή ενός signed 32-bit ακέραιου: 2.147.483.647 δευτερόλεπτα. Ένα δευτερόλεπτο αργότερα, ο ακέραιος υπερχειλίζει (overflow) στο -2.147.483.648, το οποίο τα περισσότερα λογισμικά ερμηνεύουν ως χρονική σήμανση του Δεκεμβρίου 1901. Το αποτέλεσμα μπορεί να είναι λανθασμένες ημερομηνίες, αποτυχημένες συγκρίσεις χρόνου, καταρρεύσεις προγραμμάτων, λανθασμένος προγραμματισμός εργασιών, σφάλματα πιστοποιητικών, κατεστραμμένες χρονικές σημάνσεις σε αρχεία ή βάσεις δεδομένων — και στις χειρότερες περιπτώσεις, βλάβες σε κρίσιμες υποδομές ή μακρόβιες ενσωματωμένες συσκευές.
Ενώ πολλοί υποθέτουν ότι αυτό επηρεάζει μόνο ξεπερασμένες πλατφόρμες 32-bit, όπως i586 ή armv7, πρόσφατες δοκιμές από προγραμματιστές του openSUSE και άλλους επιβεβαιώνουν ότι υπάρχει έκθεση και σε σύγχρονα συστήματα 64-bit μέσω μη ασφαλών τύπων δεδομένων, παλαιών πρωτοκόλλων και μη ενημερωμένων δυαδικών αρχείων.
Πώς η Unix Time παράγει το σφάλμα
Η Unix time ορίζεται ως ο αριθμός των δευτερολέπτων από τις 00:00:00 UTC της 1ης Ιανουαρίου 1970 (την εποχή Unix). Ιστορικά, τα συστήματα αποθήκευαν αυτήν την καταμέτρηση σε έναν signed 32-bit ακέραιο time_t. Ένας signed 32-bit ακέραιος έχει μέγιστη τιμή τα 2.147.483.647 δευτερόλεπτα → 2038-01-19 03:14:07 UTC.
Προσθέτοντας ένα ακόμα δευτερόλεπτο, προκαλείται υπερχείλιση (overflow) στο -2.147.483.648 (~1901-12-13). Από εκεί, τα συστήματα συνεχίζουν να μετρούν προς τα πάνω προς το μηδέν και στη συνέχεια μέσω θετικών ακεραίων — παράγοντας εντελώς λανθασμένες ημερομηνίες. Αυτό δεν είναι μια θεωρητική ιδιορρυθμία. Όταν προγραμματιστές του openSUSE προώθησαν το ρολόι ενός build system στο έτος 2038, πολλά πακέτα απέτυχαν να μεταγλωττιστούν ή να περάσουν τις σουίτες δοκιμών τους. Το επηρεαζόμενο λογισμικό περιλάμβανε εργαλεία ελέγχου εκδόσεων, επεξεργαστές κειμένου, μεταγλωττιστές, βιβλιοθήκες Python, εργαλεία επιφάνειας εργασίας και στοιχεία συστήματος. Σε ορισμένες περιπτώσεις, διακόπηκε ακόμη και βασική συμπεριφορά του συστήματος, όπως η αναφορά uptime.
Ποια συστήματα είναι ευάλωτα
Βασιζόμενο στις τεχνικές περιλήψεις από τα openSUSE, τη Wikipedia και αναλύσεις του κλάδου, η ευπάθεια διαιρείται σε τρεις κύκλους:
Πιθανώς ευάλωτα
Λειτουργικά συστήματα 32-bit και ABI (παλαιότερες διανομές Linux, παραλλαγές Unix, ενσωματωμένα RTOS)
Παλαιές βάσεις δεδομένων και μορφές αρχείων που αποθηκεύουν χρονικές σημάνσεις σε πεδία 32-bit (π.χ. ext2, ext3, ReiserFS)
Πολλές ενσωματωμένες συσκευές και συσκευές IoT — δρομολογητές, κάμερες IP, βιομηχανικοί ελεγκτές, ιατρικές συσκευές, ορισμένα αεροναυπηγικά συστήματα
Υλικολογισμικό (firmware) και μακρόβια βιομηχανικά/ιατρικά/αεροπορικά συστήματα
Δυαδικά αρχεία και βιβλιοθήκες τρίτων που έχουν μεταγλωττιστεί με 32-bit time_t, ακόμα και όταν εκτελούνται σε πυρήνες 64-bit
Μη ευάλωτα (εξ ορισμού)
Συστήματα που χρησιμοποιούν 64-bit time_t (τα περισσότερα λειτουργικά 64-bit, σύγχρονες εργαλειοσειρές)
Εναλλακτικές αναπαραστάσεις χρόνου (χιλιοστά ή μικροδευτερόλεπτα από την εποχή σε ακέραιους 64-bit)
Συστήματα Windows (μετρούν τον χρόνο ως διαστήματα 100 νανοδευτερολέπτων από το 1601, ισχύει έως το έτος 30.828)
macOS/iOS σε υλικό 64-bit
Πυρήνας Linux 5.6+ με _TIME_BITS=64 σε αρχιτεκτονικές 32-bit
Η γκρίζα ζώνη — Συστήματα 64-bit που εκτίθενται
Ακόμη και συστήματα 64-bit μπορεί να είναι ευάλωτα όταν:
Χρησιμοποιούν παλαιά συστήματα αρχείων χωρίς επεκτάσεις μεγάλων χρονοσφραγίδων (το ext4 απαιτεί extended inodes, το XFS χρειάζεται τη σημαία bigtime)
Χρησιμοποιούν πρωτόκολλα δικτύου όπως NFSv3, SOAP/XML‑RPC ή SNMP που κωδικοποιούν ακόμα χρονικές σημάνσεις ως τιμές 32-bit
Εκτελούν 32-bit containers ή δυαδικά αρχεία σε κεντρικούς υπολογιστές 64-bit
Χρησιμοποιούν βάσεις δεδομένων με τύπους TIMESTAMP 32-bit (ο τύπος TIMESTAMP της MySQL περιορίζεται θεμελιωδώς στο έτος 2038 απαιτείται μετεγκατάσταση σε DATETIME)
«Το γεγονός ότι ένα λειτουργικό σύστημα ή επεξεργαστής είναι 64-bit δεν σημαίνει αυτόματα ότι αποθηκεύει την ημερομηνία στην «εγγενή» μορφή bit του.» — Kaminsky, Epochalypse Now
Γιατί τα ενσωματωμένα και παλαιότερα συστήματα αποτελούν την κύρια ανησυχία
Οι ενσωματωμένες συσκευές σχεδιάζονται για μεγάλη διάρκεια ζωής — συχνά 15–20 χρόνια — και ενημερώνονται σπάνια ή είναι φυσικά δυσπρόσιτες. Συνήθη παραδείγματα περιλαμβάνουν:
Δρομολογητές και κάμερες IP
Βιομηχανικά συστήματα ελέγχου (SCADA, PLC)
Ιατρικές συσκευές (αναλυτές μυελού των οστών, αντλίες έγχυσης)
Πολλά από αυτά εκτελούν 32-bit RTOS ή userlands που εξακολουθούν να χρησιμοποιούν 32-bit time_t. Οι κατασκευαστές μπορεί να μην μπορούν να διορθώσουν κάθε συσκευή πριν από το 2038. Σε ορισμένες περιπτώσεις, η μόνη λύση είναι η αντικατάσταση υλικού.
Επιπλέον, η κρυπτογραφία προσθέτει μια μοναδική τροπή: τα πιστοποιητικά ασφαλείας γενικά αποτυγχάνουν στην επαλήθευση εάν η ημερομηνία της συσκευής είναι λανθασμένη. Μια ευάλωτη συσκευή θα μπορούσε να αποκοπεί από τις περισσότερες επικοινωνίες — ακόμα κι αν οι κύριες εφαρμογές της δεν χειρίζονται άμεσα ημερομηνίες.
Πραγματικές επιπτώσεις — Ήδη συμβαίνουν
Το πρόβλημα του έτους 2038 δεν είναι μια μακρινή αφαίρεση. Έχουν ήδη σημειωθεί αρκετές πραγματικές εκδηλώσεις:
AOLserver (2006): Μια ρύθμιση χρονικού ορίου χρησιμοποίησε ένα δισεκατομμύριο δευτερόλεπτα — ωθώντας την υπολογιζόμενη ημερομηνία πέρα από το όριο του 2038, προκαλώντας καταρρεύσεις.
Microsoft Exchange Server (2022): Ένα σφάλμα τύπου Y2K22 (σχετιζόμενο με την αντιστοίχηση Unix time 32-bit) διέκοψε παγκοσμίως τις λειτουργίες προστασίας από κακόβουλο λογισμικό.
Oracle Access Manager (2022): Ένα cookie με διάρκεια ζωής 500 εκατομμυρίων δευτερολέπτων (≈15,8 έτη) άρχισε να προκαλεί εξαιρέσεις μετά τον Μάρτιο του 2022.
Αυτο-υπογεγραμμένα πιστοποιητικά CA σε συστήματα 32-bit με ημερομηνίες λήξης μετά το 2038 αποτυγχάνουν στην επαλήθευση, σπάζοντας HTTPS και VPN.
CVE‑2025‑55068 (Dover ProGauge MagLink LX4 μετρητές δεξαμενών καυσίμου): Ο χειρισμός χρόνου προκαλεί άρνηση υπηρεσίας σε βενζινάδικα, με βαθμολογία CVSSv4 8.8.
Πιθανές αποτυχίες μετά το 2038:
Λανθασμένη καταγραφή (logging) και τηλεμετρία
Προγραμματισμένες εργασίες που δεν εκτελούνται
Ασυνέπειες χρονοσφραγίδων σε βάσεις δεδομένων και συστήματα αρχείων
Τερματικά πληρωμών και πύλες μέσων μαζικής μεταφοράς που σταματούν να λειτουργούν
Σε περιβάλλοντα κρίσιμα για την ασφάλεια (ενέργεια, μεταφορές, υγειονομική περίθαλψη, χρηματοοικονομικά): καταρράκτες λειτουργικών βλαβών
Πρόοδος και μετριασμοί ήδη σε εφαρμογή
Το θεμέλιο για την επίλυση του Y2K38 έχει τεθεί, αλλά η εργασία απέχει πολύ από το να ολοκληρωθεί.
Στοιχείο
Κατάσταση
Πυρήνας Linux
5.6 (2020) πρόσθεσε υποστήριξη χρόνου 64-bit για αρχιτεκτονικές 32-bit
GNU C Library (glibc)
2.34+ υποστηρίζει _TIME_BITS=64 σε πλατφόρμες 32-bit
NetBSD / OpenBSD
64-bit time_t για όλες τις αρχιτεκτονικές (OpenBSD 5.5+, NetBSD 6.0+)
FreeBSD
64-bit time_t για όλες εκτός από i386 32-bit
Ruby
1.9.2+ αποθηκεύει χρόνο σε signed 64-bit ακέραιο
MySQL
8.0.28+ υποστηρίζει UNIX_TIMESTAMP() 64-bit σε πλατφόρμες 64-bit
MariaDB
11.5.1+ χειρίζεται unsigned 32-bit χρονοσφραγίδες (επεκτείνεται έως το 2106)
Visual Studio
2005+ χρησιμοποιεί 64-bit time_t εκτός αν οριστεί _USE_32BIT_TIME_T
Windows API
Δεν επηρεάζεται (διαστήματα 64-bit από το 1601)
Τα συστήματα αρχείων έχουν επίσης εξελιχθεί:
ext4: με μέγεθος inode >128 bytes, επεκτείνεται έως το έτος 2446
XFS: Linux 5.10+ “big timestamps” επεκτείνεται έως το έτος 2486
NTFS, ZFS, ReFS: σχεδιάστηκαν εξαρχής με χρονοσφραγίδες 64-bit
«Τα πιο ευάλωτα συστήματα είναι εκείνα που ενημερώνονται σπάνια ή ποτέ, όπως τα παλαιότερα και τα ενσωματωμένα συστήματα.» — Wikipedia
Εναπομένοντα κενά και κίνδυνοι
Παρά αυτές τις διορθώσεις, παραμένουν σημαντικά κενά:
Συσκευές που δεν μπορούν να ενημερωθούν (χωρίς δυνατότητα αναβάθμισης υλικολογισμικού)
Παλαιά δυαδικά αρχεία που εξαρτώνται από 32-bit ABI
Βιβλιοθήκες τρίτων που δεν έχουν αναμεταγλωττιστεί με χρόνο 64-bit
Εγκαταστάσεις 32-bit που εξακολουθούν να χρησιμοποιούνται (ορισμένες περιπτώσεις χρήσης Raspberry Pi, εξειδικευμένο βιομηχανικό υλικό)
Πρωτόκολλα (NFSv3, SOAP/XML‑RPC, SNMP) που εξακολουθούν να χρησιμοποιούν χρονοσφραγίδες 32-bit
Δεν υπάρχει κοινή βάση δεδομένων ευπαθειών Y2K38 — οι προσπάθειες παραμένουν κατακερματισμένες
Η μέτρηση του συνολικού ευάλωτου πληθυσμού είναι δύσκολη, επειδή πολλά επηρεαζόμενα συστήματα είναι εκτός σύνδεσης ή ιδιόκτητα.
Πρακτικές λύσεις και προτεινόμενες ενέργειες
Για προγραμματιστές
Χρησιμοποιήστε 64-bit time_t σε νέο κώδικα (ή int64_t, long long).
Αναμεταγλωττίστε υπάρχουσες εφαρμογές με -D_TIME_BITS=64 σε glibc 2.34+.
Εκτελέστε αυτοματοποιημένες δοκιμές με ημερομηνίες πέραν του 2038. Συμπεριλάβετε ελέγχους ακραίων τιμών.
Αποφύγετε παλαιούς τύπους όπως int ή long για αποθήκευση χρόνου — δεν είναι φορητοί.
Για C++: προτιμήστε std::chrono::system_clock::time_point (64-bit σε όλες τις σύγχρονες πλατφόρμες).
Για ομάδες IT
Καταγραφή αποθέματος: Εντοπίστε συστήματα που χρησιμοποιούν πεδία χρόνου 32-bit ή εκτελούν πυρήνες/ABI 32-bit.
Ενημέρωση ή μετεγκατάσταση: Αναβαθμίστε OS, πυρήνα και libc σε εκδόσεις με υποστήριξη χρόνου 64-bit.
Αντικαταστήστε ή απομονώστε υλικό που δεν μπορεί να διορθωθεί. Προγραμματίστε ανανεώσεις υλικού για κρίσιμα συστήματα.
Επικυρώστε αντίγραφα ασφαλείας, πιστοποιητικά και προγραμματισμένες εργασίες για σωστή συμπεριφορά γύρω από πολύ μακρινές ημερομηνίες.
Ελέγξτε τα συστήματα αρχείων: Ενεργοποιήστε bigtime στο XFS. Βεβαιωθείτε ότι τα inodes του ext4 είναι αρκετά μεγάλα.
Προφυλάξεις κατά τη δοκιμή
Ποτέ μην δοκιμάζετε συστήματα παραγωγής.
Δημιουργήστε αντίγραφο ασφαλείας αμέσως πριν από τη δοκιμή.
Απομονώστε το υπό δοκιμή σύστημα από επικοινωνίες (για να μην μπερδευτούν άλλα συστήματα).
Εάν αλλάζετε ημερομηνία μέσω NTP ή GPS, βεβαιωθείτε ότι τα σήματα δοκιμής του 2038 δεν μπορούν να φτάσουν σε άλλα συστήματα.
Μετά τη δοκιμή, επαναφέρετε τη σωστή ώρα και τεκμηριώστε κάθε παρατηρούμενη συμπεριφορά.
~12 έτη (αλλά πολλά συστήματα ήδη χωρίς συντήρηση)
«Το Y2K38 συχνά απαιτεί αλλαγές ABI/πυρήνα/libc, αναμεταγλώττιση ή ενημερώσεις υλικού/υλικολογισμικού — καθιστώντας το τεχνικά δυσκολότερο σε ορισμένες στοίβες.» — Harms
Πρακτικό χρονοδιάγραμμα και προτεραιότητες
Τώρα – 2030: Συνέχιση της μετεγκατάστασης, δοκιμών και αναγνώρισης ευάλωτου αποθέματος.
2030 – 2035: Εντατικοποίηση της αποκατάστασης για εναπομείναντα παλαιά, ενσωματωμένα και μη διορθωμένα συστήματα.
2035 – 2038: Ολοκλήρωση αντικαταστάσεων για συστήματα που δεν μπορούν να διορθωθούν. Διεξαγωγή ενδελεχών δοκιμών ανακατεύθυνσης (failover) και έκτακτης ανάγκης.
2038-01-19 03:14:08 UTC: Υπερχείλιση για μη μετριασμένα συστήματα με 32-bit time_t.
Το πιο σημαντικό είναι να μην θεωρείτε το Y2K38 ως ένα μακρινό πρόβλημα του μέλλοντος. Είναι πολύ πιθανό ότι ήδη δεν διαθέτουμε αρκετό χρόνο για να εξαλείψουμε πλήρως το ελάττωμα σε κάθε ενσωματωμένη συσκευή. Ωστόσο, εντός του τεχνολογικού σας στόλου, η προσεκτική σχεδίαση και μια συστηματική προσέγγιση θα σας επιτρέψουν να προλάβετε την ημερομηνία.
Πώς η κοινότητα Ανοικτού Κώδικα αντιμετωπίζει το πρόβλημα
Έργα όπως το openSUSE εντοπίζουν και διορθώνουν ενεργά ζητήματα μέσω:
Έγκαιρων δοκιμών (προώθηση ρολογιών συστήματος κατασκευής στο 2038)
Βελτιώσεων εργαλειοσειρών (toolchain)
Συντονισμού με γνώμονα την κοινότητα
Απενεργοποίησης της υποστήριξης 32-bit (ia32) από προεπιλογή στο Leap 16
Διερεύνησης προσθηκών μεταγλωττιστή για προειδοποιήσεις επισφαλών μετατροπών μεταξύ 32-bit ακεραίων και τύπων σχετικών με τον χρόνο
Βρίσκονται σε εξέλιξη συζητήσεις για την προσθήκη προειδοποιήσεων μεταγλωττιστή όταν ο κώδικας εκτελεί επισφαλείς μετατροπές από χρόνο 64-bit σε ακέραιους 32-bit. Οι ενδιαφερόμενοι προγραμματιστές μπορούν να συμμετάσχουν στη λίστα αλληλογραφίας openSUSE Factory ή σε σχετικές συζητήσεις στο Reddit (δείτε περισσότερα εδώ).
Συμπέρασμα
Τα περισσότερα σύγχρονα συστήματα είναι ήδη ασφαλή λόγω της υποστήριξης χρόνου 64-bit σε πυρήνες, libc και συστήματα αρχείων. Η κύρια πρόκληση παραμένουν τα παλαιότερα και ενσωματωμένα συστήματα που δεν μπορούν να ενημερωθούν εύκολα. Η τεχνική λύση — η μετάβαση σε “χρονοσφραγίδες 64-bit — είναι εννοιολογικά απλή, αλλά η ευρεία αποκατάσταση απαιτεί καταγραφή αποθέματος, συνεργασία με προμηθευτές, ενημερώσεις υλικολογισμικού ή αντικατάσταση υλικού.
Με συντονισμένη δράση τώρα, οι χειρότερες επιπτώσεις μπορούν να αποφευχθούν πολύ πριν από το 2038. Το Epochalypse δεν είναι λόγος πανικού, αλλά είναι λόγος για μεθοδική επαλήθευση σύστημα προς σύστημα. Ξεκινήστε σήμερα: ελέγξτε τις αναπαραστάσεις χρόνου σας, δοκιμάστε τα πιο κρίσιμα συστήματά σας και βεβαιωθείτε ότι κάθε συσκευή από την οποία εξαρτάστε θα γνωρίζει ακόμα τι έτος είναι όταν φτάσει η 19η Ιανουαρίου 2038.
Μετά την επιτυχία της πρώτης διοργάνωσης, το PyCon Greece επιστρέφει για τη 2η χρονιά του, φέρνοντας ξανά κοντά την ελληνική και διεθνή κοινότητα της Python. Το συνέδριο θα πραγματοποιηθεί στις 12–13 Οκτωβρίου 2026 στην Τεχνόπολη Δήμου Αθηναίων — έναν από τους πιο δυναμικούς πολιτιστικούς χώρους της πρωτεύουσας, όπου η βιομηχανική κληρονομιά συναντά τη σύγχρονη δημιουργικότητα και την τεχνολογία.
Τι είναι το PyCon Greece
Το PyCon Greece είναι ένα συνέδριο αφιερωμένο στη γλώσσα προγραμματισμού Python και στην κοινότητα που την περιβάλλει. Διοργανώνεται από το PyGreece, την επίσημη ελληνική κοινότητα Python, και υλοποιείται από μια εθελοντική ομάδα με στόχο την ανταλλαγή γνώσης και τη συνεργασία μεταξύ ατόμων που χρησιμοποιούν την Python — ανεξαρτήτως επαγγελματικής ιδιότητας ή χρόνων εμπειρίας.
Το πρόγραμμα περιλαμβάνει δύο ημέρες με παράλληλες ομιλίες, hands-on σεμινάρια (tutorials), συζητήσεις πάνελ και άφθονες ευκαιρίες δικτύωσης. Οι διοργανωτές δεσμεύονται ρητά για ένα συμπεριληπτικό περιβάλλον χωρίς αποκλεισμούς, όπου κάθε άτομο είναι ευπρόσδεκτο.
Ανοιχτή η Πρόσκληση Υποβολής Προτάσεων (Call for Proposals)
Το Call for Proposals είναι ανοιχτό. Αν χρησιμοποιείς την Python με ουσιαστικό τρόπο — στην έρευνα, τη βιομηχανία, την εκπαίδευση, την τέχνη ή τον ακτιβισμό — η ομάδα του PyCon Greece θέλει να ακούσει την ιστορία σου.
Αξίζει να τονιστεί ότι η πρόσκληση απευθύνεται σε όλα τα άτομα, ακόμη και σε όσα δεν έχουν προηγούμενη εμπειρία σε συνέδρια. Όπως σημειώνουν οι διοργανωτές, δεν μετράει η καταξίωση αλλά το να έχεις κάτι ουσιαστικό να μοιραστείς. Μάλιστα, υπάρχει ιδιαίτερη ενθάρρυνση προς άτομα από υποεκπροσωπούμενες ομάδες της κοινότητας, καθώς και ένα Speaker Mentorship Program για όσες και όσους θέλουν υποστήριξη στα πρώτα τους βήματα.
Χρονοδιάγραμμα CFP
14 Απριλίου 2026: Άνοιγμα Call for Proposals
10–11 Μαΐου 2026: Κλείσιμο Call for Proposals
15 Ιουνίου 2026: Ειδοποιήσεις στους ομιλητές/τριες
30 Ιουνίου 2026: Προθεσμία επιβεβαίωσης συμμετοχής
31 Ιουλίου 2026: Δημοσίευση προγράμματος
12–13 Οκτωβρίου 2026: PyCon Greece 2026
Θεματικές ενότητες
Οι προτάσεις μπορούν να αφορούν ένα ευρύ φάσμα θεμάτων:
Κυκλοφόρησε η νέα έκδοση, 26.04, της διανομής Ubuntu! Μπορείτε να την κατεβάσετε από το επίσημο site. Μην ξεχάσετε να ρίξετε μια ματιά στις σημειώσεις της έκδοσης πρίν την αναβάθμιση ή την εγκατάσταση. Υπενθυμίζουμε ότι βγαίνει σε πολλές "γεύσεις" ;-)
Η πρόταση για το λεγόμενο Digital Omnibus αποτελεί μια από τις πιο φιλόδοξες – αλλά και αμφιλεγόμενες – προσπάθειες της Ευρωπαϊκής Ένωσης να αναθεωρήσει το ισχύον πλαίσιο διακυβέρνησης δεδομένων. Αν και μεγάλο μέρος της δημόσιας συζήτησης επικεντρώνεται στις αλλαγές που αφορούν τον Γενικό Κανονισμό για την Προστασία Δεδομένων (GDPR), τους κανόνες για την ιδιωτικότητα στις ηλεκτρονικές επικοινωνίες και την τεχνητή νοημοσύνη, η πραγματική εμβέλεια της πρότασης είναι πολύ ευρύτερη.
Μια βαθιά αναδιάρθρωση του “data acquis”
Το Digital Omnibus δεν περιορίζεται σε επιμέρους τροποποιήσεις. Επιχειρεί να συγχωνεύσει και να αναδιαμορφώσει το λεγόμενο “data acquis” της ΕΕ, δηλαδή το σύνολο των νόμων και κανόνων που ρυθμίζουν την πρόσβαση, τη διαχείριση και την επαναχρησιμοποίηση δεδομένων. Συγκεκριμένα, ενσωματώνει στοιχεία από τον Data Governance Act και την Open Data Directive μέσα στο Data Act, μετατρέποντάς τον σε κεντρικό πυλώνα για όλα τα ζητήματα που σχετίζονται με τα δεδομένα.
Αυτή η αλλαγή δεν είναι απλώς τεχνική. Ανατρέπει την ισορροπία μεταξύ διαφορετικών μηχανισμών διακυβέρνησης, επηρεάζοντας τον τρόπο με τον οποίο:
οι δημόσιες αρχές αποκτούν πρόσβαση σε ιδιωτικά δεδομένα,
λειτουργούν οι ενδιάμεσοι φορείς δεδομένων,
και επαναχρησιμοποιούνται τα δεδομένα του δημόσιου τομέα.
Το βασικό πρόβλημα είναι ότι οι νόμοι που τροποποιούνται είναι πολύ πρόσφατοι και δεν έχουν ακόμη εφαρμοστεί πλήρως στην πράξη. Η πρόωρη αναθεώρησή τους ενδέχεται να δημιουργήσει περισσότερη αβεβαιότητα παρά βελτίωση.
Κίνδυνος αποδυνάμωσης των εγγυήσεων
Το αρχικό ευρωπαϊκό πλαίσιο δεδομένων σχεδιάστηκε με στόχο να επιτύχει μια λεπτή ισορροπία: να ενισχύσει τη διαμοίραση δεδομένων χωρίς να υπονομεύσει τα θεμελιώδη δικαιώματα, τη διαφάνεια και τον ανταγωνισμό. Το Digital Omnibus, ωστόσο, φαίνεται να μετατοπίζει αυτή την ισορροπία.
Η μεταφορά μηχανισμών διακυβέρνησης από το Data Governance Act στο Data Act – ένα εργαλείο με διαφορετική φιλοσοφία, πιο προσανατολισμένη στην πρόσβαση και αξιοποίηση δεδομένων – ενδέχεται να αποδυναμώσει τις προστασίες που είχαν σχεδιαστεί για πιο ευαίσθητα πλαίσια χρήσης.
Παράλληλα, βασικές έννοιες παραμένουν ασαφείς, όπως το τι ακριβώς συνιστά «πρόσβαση σε δεδομένα» ή «χώρο δεδομένων». Αυτή η ασάφεια δυσκολεύει την εφαρμογή των κανόνων και ανοίγει τον δρόμο για άνιση συμμόρφωση.
Η θέση του GDPR σε κίνδυνο
Ένα από τα πιο κρίσιμα ζητήματα αφορά τη σχέση του νέου πλαισίου με τον GDPR. Οι υφιστάμενοι κανονισμοί είχαν σχεδιαστεί ώστε να λειτουργούν συμπληρωματικά προς αυτόν, όχι να τον υποκαθιστούν.
Ωστόσο, με τη συγχώνευση διαφορετικών μηχανισμών, υπάρχει ο κίνδυνος να δημιουργηθούν «παράλληλα καθεστώτα» επεξεργασίας δεδομένων. Αυτό μπορεί να οδηγήσει σε σύγχυση σχετικά με:
το ποιος είναι υπεύθυνος για τη συμμόρφωση,
ποια νομική βάση ισχύει,
και πώς προστατεύονται τα δικαιώματα των πολιτών.
Σε ένα τέτοιο περιβάλλον, βασικές αρχές όπως η διαφάνεια, ο περιορισμός σκοπού και η λογοδοσία ενδέχεται να αποδυναμωθούν.
Περιορισμένη πρόσβαση δεδομένων για το δημόσιο συμφέρον
Το Digital Omnibus περιορίζει σημαντικά τη δυνατότητα των δημόσιων αρχών να έχουν πρόσβαση σε ιδιωτικά δεδομένα, επιτρέποντάς την κυρίως σε περιπτώσεις έκτακτης ανάγκης. Αυτό δημιουργεί ένα σημαντικό κενό, καθώς πολλές χρήσεις δεδομένων προς όφελος της κοινωνίας – όπως η περιβαλλοντική παρακολούθηση ή η επιστημονική έρευνα – δεν εμπίπτουν σε τέτοιες καταστάσεις.
Ως αποτέλεσμα, οι δημόσιες αρχές ενδέχεται να εξαρτώνται περισσότερο από εθελοντικές συμφωνίες με μεγάλες εταιρείες, γεγονός που ενισχύει τη συγκέντρωση ισχύος και περιορίζει την ανεξαρτησία της εποπτείας.
Αποδυνάμωση της “αρχιτεκτονικής εμπιστοσύνης”
Ένα ακόμη σημαντικό στοιχείο είναι η αλλαγή στον ρόλο των ενδιάμεσων φορέων δεδομένων. Η υποχρεωτική εγγραφή τους – που λειτουργούσε ως εγγύηση αξιοπιστίας – γίνεται πλέον προαιρετική. Αυτό ενδέχεται να μετατρέψει την έννοια της «εμπιστοσύνης» σε τυπικό χαρακτηριστικό χωρίς ουσιαστικό περιεχόμενο.
Με αυτόν τον τρόπο:
οι μεγάλοι παίκτες ενισχύονται,
οι μικρότεροι χάνουν ανταγωνιστικό πλεονέκτημα,
και η αγορά γίνεται λιγότερο διαφανής.
Η ανάγκη για σαφήνεια και ισορροπία
Το βασικό ζητούμενο για το μέλλον της ευρωπαϊκής διακυβέρνησης δεδομένων είναι η διατήρηση της ισορροπίας μεταξύ καινοτομίας και προστασίας. Αυτό προϋποθέτει:
σαφείς κανόνες και ορισμούς,
διακριτούς ρόλους για κάθε νομικό εργαλείο,
και ισχυρούς μηχανισμούς εφαρμογής.
Χωρίς αυτά, η απλοποίηση που επιδιώκει το Digital Omnibus κινδυνεύει να οδηγήσει σε μεγαλύτερη πολυπλοκότητα και αβεβαιότητα.
Το Digital Omnibus αποτελεί μια σημαντική καμπή για το ευρωπαϊκό πλαίσιο δεδομένων. Αν και επιδιώκει την απλοποίηση και την ενίσχυση της αξιοποίησης δεδομένων, ενέχει σοβαρούς κινδύνους: αποδυνάμωση των εγγυήσεων, σύγχυση στους κανόνες και ενίσχυση της συγκέντρωσης ισχύος.
Η πρόκληση για την Ευρωπαϊκή Ένωση είναι να διασφαλίσει ότι οποιαδήποτε μεταρρύθμιση θα ενισχύει – και δεν θα υπονομεύει – τη διαφάνεια, τη δημοκρατική λογοδοσία και τα δικαιώματα των πολιτών.
Ξεκινά σήμερα στην Αθήνα το Drupal Developer Days 2026, η 16η ετήσια διοργάνωση της παγκόσμιας κοινότητας του Drupal, η οποία θα φιλοξενηθεί από τις 22 έως τις 25 Απριλίου 2026 στις σύγχρονες εγκαταστάσεις της OTE Academy στο Μαρούσι. Για τέσσερις ημέρες, η Αθήνα μετατρέπεται σε κόμβο της ευρωπαϊκής κοινότητας ανοιχτού λογισμικού, υποδεχόμενη developers, site builders, contributors και στελέχη από όλο τον κόσμο για workshops, sessions, contribution sprints και δράσεις ανταλλαγής τεχνογνωσίας γύρω από το δημοφιλές σύστημα διαχείρισης περιεχομένου Drupal.
Ο Οργανισμός Ανοιχτών Τεχνολογιών – ΕΕΛΛΑΚ συμμετέχει στη διοργάνωση ως In-Kind sponsor, στηρίζοντας τόσο το τεχνικό περιεχόμενο του συνεδρίου όσο και τη συμμετοχή νέων από την εκπαιδευτική κοινότητα.
Στο πλαίσιο του συνεδρίου, η ΕΕΛΛΑΚ συνεισφέρει με δύο στοχευμένες συζητήσεις BoF που αγγίζουν κρίσιμα ζητήματα για τον ελληνικό δημόσιο τομέα και την αξιοποίηση ανοιχτών δεδομένων:
1. «Unlocking Public Drupal Content as AI-Ready Open Data with GlossAPI»
Ομιλήτρια: Μυρσίνη Ιωάννου (ΕΕΛΛΑΚ/GFOSS)
Πέμπτη 23 Απριλίου, 12:15–12:55, Room 5 (BoF)
Η παρουσίαση εστιάζει στο πώς οι πλατφόρμες του δημόσιου τομέα που βασίζονται στο Drupal μπορούν να μετατρέψουν το δομημένο περιεχόμενό τους σε καθαρά, τεκμηριωμένα και επαναχρησιμοποιήσιμα datasets μέσω του εργαλείου GlossAPI, ενισχύοντας τη διαφάνεια, τα ανοιχτά δεδομένα και τις εφαρμογές τεχνητής νοημοσύνης.
2. «Building a Greek ‘Gov.drupal’ Distribution: Open Source as a Mandate»
Ομιλητής: Παναγιώτης Σκαρβέλης (ΕΕΛΛΑΚ/GFOSS)
Παρασκευή 24 Απριλίου, 15:45–16:25, Room 5 (BoF)
Η συνεδρία θέτει το ερώτημα αν το Drupal μπορεί να αποτελέσει το standard CMS για τα έργα του ελληνικού δημοσίου και ανοίγει μια συζήτηση για τη δημιουργία μιας ελληνικής «Gov.drupal» διανομής, με βάση αντίστοιχες καλές πρακτικές από άλλες ευρωπαϊκές χώρες.
Επίσης στο πλαίσιο της αποστολής της για την προώθηση των ανοιχτών τεχνολογιών στην εκπαίδευση, η ΕΕΛΛΑΚ κάλυψε τα έξοδα μετακίνησης και διαμονής επιλεγμένων φοιτητών που διαμένουν εκτός Αττικής, ώστε να διευκολυνθεί η συμμετοχή τους στο εκπαιδευτικό εργαστήριο «Drupal in a Day». Η κάλυψη των εξόδων μετακίνησης κατέστη εφικτή χάρη στη χορηγία της Agency Trust, την οποία η ΕΕΛΛΑΚ ευχαριστεί θερμά για την έμπρακτη στήριξη της νέας γενιάς developers.
Το «Drupal in a Day» είναι ένα εντατικό, μονοήμερο εργαστήριο που εισάγει φοιτητές και νέους επαγγελματίες στο Drupal ως σύστημα διαχείρισης περιεχομένου, προσφέροντάς τους hands-on εμπειρία και επαφή με τη διεθνή κοινότητα.
Η Γαλλία κάνει ένα σημαντικό βήμα προς την ενίσχυση της ψηφιακής της ανεξαρτησίας, επιλέγοντας να απομακρυνθεί από ιδιόκτητα λειτουργικά συστήματα και να στραφεί σε λύσεις ανοιχτού λογισμικού, με βασικό άξονα το Linux. Η απόφαση αυτή, που ανακοινώθηκε στις 8 Απριλίου από τη Διυπουργική Διεύθυνση Ψηφιακών Υποθέσεων (DINUM), εντάσσεται σε μια ευρύτερη στρατηγική για τη μείωση της εξάρτησης από μη ευρωπαϊκές τεχνολογίες.
Ψηφιακή Κυριαρχία και Μείωση Εξαρτήσεων
Η πρωτοβουλία αυτή προέκυψε έπειτα από διακυβερνητικό σεμινάριο με τη συμμετοχή κορυφαίων κρατικών φορέων, όπως η Εθνική Υπηρεσία Κυβερνοασφάλειας (ANSSI) και η Γενική Διεύθυνση Επιχειρήσεων (DGE). Κοινός στόχος ήταν η ενίσχυση της ψηφιακής κυριαρχίας της Γαλλίας και της Ευρώπης μέσω της μείωσης της εξάρτησης από ξένες τεχνολογικές λύσεις.
Στο πλαίσιο αυτό, κάθε υπουργείο καλείται να εντοπίσει τις κρίσιμες τεχνολογικές του εξαρτήσεις και να εκπονήσει σχέδιο δράσης μέχρι το φθινόπωρο. Οι τομείς προτεραιότητας περιλαμβάνουν τους σταθμούς εργασίας, τα συνεργατικά εργαλεία, τα λογισμικά προστασίας από ιούς, τις βάσεις δεδομένων και τις υποδομές δικτύων.
Ο Ρόλος του Ανοιχτού Λογισμικού
Η στροφή προς το ανοιχτό λογισμικό δεν είναι καινούργια για τη Γαλλία. Η DINUM έχει ήδη αναπτύξει τη σουίτα εργαλείων LaSuite (πρώην La Suite Numérique), η οποία χρησιμοποιείται από περίπου 600.000 δημόσιους υπαλλήλους. Η μετάβαση των 234 διαχειριστών της υπηρεσίας σε Linux αποτελεί ένα ακόμη βήμα προς αυτή την κατεύθυνση, μετά από τρία χρόνια προετοιμασίας και δοκιμών.
Άλλοι δημόσιοι οργανισμοί, όπως η Εθνική Χωροφυλακή και η Γενική Διεύθυνση Δημόσιων Οικονομικών, έχουν ήδη υιοθετήσει το Linux, επισημαίνοντας την απώλεια ελέγχου που συνεπάγεται η χρήση ιδιόκτητων συστημάτων.
Προκλήσεις και Ανθρώπινος Παράγοντας
Η μετάβαση σε νέα ψηφιακά περιβάλλοντα δεν είναι χωρίς δυσκολίες. Σύμφωνα με τη DINUM, ο ανθρώπινος παράγοντας είναι κρίσιμος για την επιτυχία τέτοιων εγχειρημάτων. Η εκπαίδευση και η υποστήριξη των χρηστών είναι απαραίτητες ώστε να εξασφαλιστεί η ομαλή προσαρμογή.
Επιπλέον, δίνεται έμφαση στον σχεδιασμό εύχρηστων και ελκυστικών εργαλείων. Όπως τονίζεται, η αποδοχή από τους χρήστες εξαρτάται σε μεγάλο βαθμό από την εμπειρία χρήσης, γεγονός που καθιστά τη συνεργασία μεταξύ προγραμματιστών και σχεδιαστών απαραίτητη.
Ευρωπαϊκή Συνεργασία και Προοπτικές
Η ανάπτυξη της LaSuite πραγματοποιήθηκε σε συνεργασία με χώρες όπως η Ολλανδία και η Γερμανία, στο πλαίσιο της Ευρωπαϊκής Πρωτοβουλίας Ψηφιακών Υποδομών (EDIC). Στόχος είναι η αποφυγή κατακερματισμού και η δημιουργία κοινών προτύπων σε ευρωπαϊκό επίπεδο.
Η μετάβαση στο Linux δεν αποτελεί απλώς μια τεχνική επιλογή, αλλά μια στρατηγική απόφαση με ευρύτερες γεωπολιτικές και οικονομικές προεκτάσεις. Μέσω αυτής, η Γαλλία επιδιώκει να ενισχύσει τη διαφάνεια, να αποκτήσει μεγαλύτερο έλεγχο στα ψηφιακά της συστήματα και να ενδυναμώσει την εγχώρια και ευρωπαϊκή τεχνολογική βιομηχανία.
Στον χώρο του ελεύθερου και ανοικτού λογισμικού, δύο βασικές έννοιες που καθορίζουν τον τρόπο διάθεσης και χρήσης του κώδικα είναι η επανααδειοδότηση (relicensing) και η συμβατότητα αδειών (license compatibility). Αν και σχετίζονται μεταξύ τους, πρόκειται για διαφορετικές διαδικασίες με ξεχωριστή σημασία.
Τι είναι η επανααδειοδότηση;
Η επανααδειοδότηση αναφέρεται στη δυνατότητα αλλαγής της άδειας χρήσης ενός έργου λογισμικού. Το δικαίωμα αυτό ανήκει αποκλειστικά στον κάτοχο των πνευματικών δικαιωμάτων. Όταν ένας δημιουργός δημοσιεύει το έργο του με μια ελεύθερη άδεια, όπως η GNU GPL ή η Mozilla Public License 2.0, επιτρέπει στην κοινότητα να το χρησιμοποιεί, να το μελετά, να το τροποποιεί και να το διανέμει υπό συγκεκριμένους όρους.
Ωστόσο, μόνο ο ίδιος ο κάτοχος των δικαιωμάτων μπορεί να αλλάξει αυτούς τους όρους εκδίδοντας το έργο με διαφορετική άδεια στο μέλλον. Αν υπάρχουν πολλοί συν-δημιουργοί, απαιτείται η συναίνεση όλων.
Ειδική περίπτωση: επιτρεπόμενη επανααδειοδότηση
Σε ορισμένες περιπτώσεις, ο δημιουργός μπορεί να επιτρέψει στους χρήστες να διανέμουν το έργο υπό εναλλακτικούς όρους. Για παράδειγμα, ένα έργο μπορεί να δημοσιευτεί ως “GNU GPL έκδοση 2 ή νεότερη”, δίνοντας τη δυνατότητα στον χρήστη να επιλέξει και τη GNU GPLv3.
Εδώ όμως υπάρχει μια σημαντική διάκριση:
Η πραγματική επανααδειοδότηση γίνεται μόνο από τον κάτοχο των δικαιωμάτων.
Οι χρήστες απλώς αξιοποιούν μια επιλογή που τους έχει ήδη δοθεί.
Τι είναι η συμβατότητα αδειών;
Η συμβατότητα αδειών αφορά το αν δύο διαφορετικά έργα λογισμικού μπορούν να συνδυαστούν και να διανεμηθούν μαζί. Αυτό είναι εφικτό μόνο όταν οι όροι των αδειών τους δεν συγκρούονται.
Παράδειγμα συμβατότητας
Η Modified BSD License θεωρείται συμβατή με την GNU GPLv3. Αυτό συμβαίνει επειδή οι όροι της BSD (όπως η διατήρηση ειδοποιήσεων πνευματικών δικαιωμάτων και αποποίησης ευθυνών) δεν έρχονται σε αντίθεση με τις απαιτήσεις της GPL.
Έτσι, μπορούμε να συνδυάσουμε:
ένα πρόγραμμα υπό GNU GPLv3
και ένα άλλο υπό Modified BSD
και να τα διανείμουμε ως ένα ενιαίο έργο, αρκεί να τηρούμε όλους τους όρους και των δύο αδειών.
Τα τελευταία χρόνια, η Ευρωπαϊκή Ένωση έχει κάνει σημαντικά βήματα προς την αξιοποίηση των δημόσιων δεδομένων, περνώντας από το στάδιο του σχεδιασμού στην πρακτική εφαρμογή. Κεντρικό ρόλο σε αυτή τη μετάβαση διαδραματίζει το νέο πλαίσιο για τα «δεδομένα υψηλής αξίας» (High Value Datasets – HVDs), το οποίο τέθηκε σε ισχύ το 2024 μέσω του Εκτελεστικού ... Read more
Οι εκδηλώσεις δεν σταματούν καθώς αυτήν την εβδομάδα πραγματοποιούνται εκδηλώσεις στην Ελλάδα και στο εξωτερικό για τις ανοιχτές τεχνολογίες και την καινοτομία! Ο Οργανισμός Ανοιχτών Τεχνολογιών (ΕΕΛΛΑΚ) σας προτείνει να τις παρακολουθήσετε και να τις διαδώσετε. Μπορείτε επίσης να δείτε περισσότερες εκδηλώσεις για τις επόμενες εβδομάδες ή να καταχωρίσετε τη δική σας εκδήλωση στο: https://ellak.gr/events.
Σας προσκαλούμε στο ανοικτό διαδικτυακό webinar «S.T.E.P.S. School Box: Ένα ανοικτό ψηφιακό περιβάλλον για τη διδασκαλία STEM», στο πλαίσιο του ευρωπαϊκού έργου S.T.E.P.S.
Τη Δευτέρα 27 Απριλίου 2026, στις 16:00-18:00, θα γίνει παρουσίαση του S.T.E.P.S. School Box (https://moocsteps.eu/) — μιας συλλογής ανοικτών μαθημάτων και εκπαιδευτικών δραστηριοτήτων για τη πρωτοβάθμια και δευτεροβάθμια εκπαίδευση, οργανωμένη σε τέσσερις θεματικές: Προγραμματισμός, Τεχνολογία, Αειφορία και Μηχανική.
Κεντρικό εργαλείο του υλικού είναι το FOSSBot, το ανοικτού κώδικα εκπαιδευτικό ρομπότ, που λειτουργεί ως διαθεματικό μέσο σύνδεσης Φυσικής, Μαθηματικών και Πληροφορικής στην εκπαιδευτική πράξη.
Η πλατφόρμα https://moocsteps.eu/ αποτελεί ένα ολοκληρωμένο περιβάλλον επιμόρφωσης στη διδασκαλία STEM, με έμφαση στη ρομποτική και την αξιοποίηση σύγχρονων ψηφιακών εργαλείων. Περιλαμβάνει δομημένες θεματικές ενότητες, πρακτικές δραστηριότητες, έτοιμα σχέδια μαθήματος και διαδραστικό εκπαιδευτικό υλικό, τα οποία υποστηρίζουν τη μάθηση μέσω έργων (project-based learning) και τη διαθεματική προσέγγιση. Το περιεχόμενο είναι ανοικτό και επαναχρησιμοποιήσιμο, δίνοντας στους εκπαιδευτικούς τη δυνατότητα να προσαρμόζουν τις δραστηριότητες στις ανάγκες της τάξης τους.
Για τους εκπαιδευτικούς, το βασικό όφελος είναι η άμεση δυνατότητα εφαρμογής στην εκπαιδευτική πράξη, χωρίς να απαιτείται προηγούμενη εξειδίκευση στη ρομποτική ή τον προγραμματισμό. Μέσα από την πλατφόρμα αποκτούν πρακτικές δεξιότητες, παιδαγωγική καθοδήγηση και έτοιμα εργαλεία που ενισχύουν την ενσωμάτωση του STEM στη διδασκαλία, συμβάλλοντας παράλληλα στην ανάπτυξη ψηφιακών και διδακτικών ικανοτήτων. Η ευελιξία της ασύγχρονης παρακολούθησης και η δωρεάν πρόσβαση καθιστούν την επιμόρφωση προσιτή και λειτουργική για το σύνολο της εκπαιδευτικής κοινότητας.
Κατά τη διάρκεια του Webinar θα παρουσιαστούν επιπλέον:
Η φιλοσοφία και η μεθοδολογία ανάπτυξης του S.T.E.P.S. School Box
Η δομή και τα βασικά χαρακτηριστικά του εκπαιδευτικού υλικού
Η λειτουργία της ψηφιακής πλατφόρμας (MOOC) και τα πολυγλωσσικά της χαρακτηριστικά
Τα αποτελέσματα της πιλοτικής εφαρμογής και τα συμπεράσματα από τη διαδικασία αξιολόγησης
Παραδείγματα δραστηριοτήτων και τρόποι ενσωμάτωσης στην εκπαιδευτική πράξη
Η εκδήλωση απευθύνεται σε εκπαιδευτικούς όλων των βαθμίδων, καθώς και σε φοιτητές και ερευνητές που ενδιαφέρονται για την καινοτόμο διδασκαλία STEM και τους ανοικτούς εκπαιδευτικούς πόρους.
Θα αποσταλεί βεβαίωση παρακολούθησης σε όσους συμμετάσχουν.
Για να δηλώσετε συμμετοχή, συμπληρώστε τη φόρμα εγγραφής.
Οι ειδοποιήσεις στο κινητό μας τηλέφωνο αποτελούν πλέον αναπόσπαστο μέρος της καθημερινότητάς μας. Μας ενημερώνουν για μηνύματα, emails, ειδήσεις και δραστηριότητες σε εφαρμογές. Ωστόσο, πίσω από αυτή τη φαινομενική ευκολία κρύβονται σημαντικοί κίνδυνοι για την ιδιωτικότητα των χρηστών.
Πού βρίσκεται το πρόβλημα;
Οι ειδοποιήσεις μπορούν να αποκαλύψουν πολλά περισσότερα από όσα φανταζόμαστε: ποιος μας έστειλε μήνυμα, τι περιέχει, πότε το λάβαμε και ποιες εφαρμογές χρησιμοποιούμε. Αυτές οι πληροφορίες μπορεί να γίνουν προσβάσιμες σε τρίτους με διάφορους τρόπους.
Υπάρχουν δύο βασικά σημεία κινδύνου:
1. Κατά τη μεταφορά μέσω cloud Οι περισσότερες ειδοποιήσεις δεν αποστέλλονται απευθείας από την εφαρμογή στο κινητό σας. Αντίθετα, περνούν πρώτα από διακομιστές εταιρειών όπως η Apple ή η Google. Αυτό σημαίνει ότι ενδέχεται να έχουν πρόσβαση σε μεταδεδομένα (π.χ. ποια εφαρμογή έστειλε ειδοποίηση και πότε), ενώ σε ορισμένες περιπτώσεις μπορεί να είναι ορατό ακόμη και το περιεχόμενο.
2. Στη συσκευή σας Ακόμη και μετά τη λήψη τους, οι ειδοποιήσεις μπορεί να εμφανίζονται στην οθόνη κλειδώματος. Αν κάποιος αποκτήσει πρόσβαση στη συσκευή σας —είτε μέσω κλοπής είτε μέσω κατάσχεσης— μπορεί να δει ευαίσθητες πληροφορίες χωρίς να την ξεκλειδώσει.
Επιπλέον, ακόμη και αν διαγράψετε μια ειδοποίηση, το περιεχόμενό της ενδέχεται να παραμένει αποθηκευμένο στη συσκευή και να μπορεί να ανακτηθεί με ειδικά εργαλεία.
Τι μπορείτε να κάνετε για να προστατευτείτε
Παρόλο που οι κίνδυνοι είναι υπαρκτοί, υπάρχουν τρόποι να περιορίσετε την έκθεσή σας.
1. Ρυθμίστε τις ειδοποιήσεις στις εφαρμογές μηνυμάτων Εφαρμογές όπως το Signal και το WhatsApp προσφέρουν επιλογές για το τι εμφανίζεται στις ειδοποιήσεις:
Πλήρες περιεχόμενο μηνύματος
Μόνο το όνομα αποστολέα
Καμία πληροφορία (ούτε όνομα ούτε περιεχόμενο)
Η επιλογή της τελευταίας είναι η πιο ασφαλής.
2. Περιορίστε την εμφάνιση στην οθόνη κλειδώματος Μπορείτε να επιλέξετε:
Να εμφανίζονται πάντα
Να εμφανίζονται μόνο όταν η συσκευή είναι ξεκλείδωτη
Να μην εμφανίζεται καθόλου περιεχόμενο
Η επιλογή “μόνο όταν είναι ξεκλείδωτη” αποτελεί μια καλή ισορροπία μεταξύ ευκολίας και ασφάλειας.
3. Απενεργοποιήστε περιττές ειδοποιήσεις Όσο λιγότερες εφαρμογές στέλνουν ειδοποιήσεις, τόσο μικρότερος ο κίνδυνος διαρροής δεδομένων. Αναρωτηθείτε: χρειάζομαι πραγματικά ειδοποιήσεις από αυτή την εφαρμογή;
4. Ελέγξτε τις ρυθμίσεις απορρήτου σε Android και iOS Και τα δύο λειτουργικά συστήματα παρέχουν επιλογές για:
Απόκρυψη ευαίσθητου περιεχομένου
Διαχείριση ειδοποιήσεων ανά εφαρμογή
Απενεργοποίηση ειδοποιήσεων πλήρως
5. Προσοχή στις λειτουργίες τεχνητής νοημοσύνης Ορισμένα συστήματα συνοψίζουν ειδοποιήσεις χρησιμοποιώντας AI. Αν αυτές οι λειτουργίες στέλνουν δεδομένα σε servers, ενδέχεται να αυξάνεται ο κίνδυνος παραβίασης ιδιωτικότητας.
Οι ειδοποιήσεις είναι χρήσιμες, αλλά δεν είναι αθώες. Μπορούν να αποτελέσουν πηγή διαρροής προσωπικών δεδομένων, τόσο μέσω εταιρειών τεχνολογίας όσο και μέσω φυσικής πρόσβασης στη συσκευή.
Η σωστή διαχείριση των ρυθμίσεων, η επιλογή ασφαλών εφαρμογών και η μείωση των περιττών ειδοποιήσεων μπορούν να κάνουν σημαντική διαφορά.
Σε έναν κόσμο όπου η ψηφιακή ιδιωτικότητα απειλείται όλο και περισσότερο, ακόμα και οι μικρές λεπτομέρειες —όπως μια ειδοποίηση στην οθόνη— έχουν σημασία.
Η ψηφιακή μετάβαση της Ευρώπης αποτελεί βασική προτεραιότητα για την ενίσχυση της ανταγωνιστικότητας, της καινοτομίας και της εξυπηρέτησης των πολιτών. Σε αυτό το πλαίσιο, η Ευρωπαϊκή Επιτροπή έχει αναπτύξει τα «Ψηφιακά Δομικά Στοιχεία για την Ευρώπη» (Digital Building Blocks), μια σειρά από επαναχρησιμοποιήσιμες ψηφιακές λύσεις που επιτρέπουν τη δημιουργία ασφαλών και διαλειτουργικών δημόσιων υπηρεσιών σε ολόκληρη την Ευρωπαϊκή Ένωση.
Τα ψηφιακά δομικά στοιχεία αποτελούν ανοιχτές και ευέλικτες λύσεις που έχουν σχεδιαστεί για να αντιμετωπίζουν κοινές προκλήσεις στη λειτουργία των δημόσιων υπηρεσιών. Αντί οι οργανισμοί να δημιουργούν νέα συστήματα από την αρχή, μπορούν να αξιοποιούν ήδη υπάρχοντα εργαλεία και υποδομές που συμμορφώνονται με τα ευρωπαϊκά πρότυπα. Αυτές οι λύσεις περιλαμβάνουν λογισμικό, τεχνικά πρότυπα, πλαίσια ανάπτυξης και υπηρεσίες cloud.
Ενδεικτικά, τα δομικά στοιχεία καλύπτουν κρίσιμους τομείς όπως η ηλεκτρονική ταυτοποίηση (eID), που επιτρέπει στους χρήστες να αποδεικνύουν την ταυτότητά τους διαδικτυακά, τα συστήματα ασφαλούς ανταλλαγής δεδομένων, οι ηλεκτρονικές υπογραφές για την ψηφιακή επικύρωση εγγράφων και η ηλεκτρονική τιμολόγηση που απλοποιεί τις οικονομικές διαδικασίες. Όλες αυτές οι λύσεις έχουν εγκριθεί από την Ευρωπαϊκή Επιτροπή και είναι σχεδιασμένες ώστε να ευθυγραμμίζονται με τη νομοθεσία της ΕΕ, συμβάλλοντας στη μείωση κόστους και χρόνου υλοποίησης.
Παράλληλα, τα ψηφιακά δομικά στοιχεία ενισχύουν τη διαφάνεια και την καινοτομία μέσω της προώθησης των ανοιχτών δεδομένων και της διασυνοριακής ανταλλαγής πληροφοριών. Η διαλειτουργικότητα των συστημάτων επιτρέπει στις δημόσιες διοικήσεις να μοιράζονται δεδομένα με ασφάλεια, να επαναχρησιμοποιούν πληροφορίες και να συνδυάζουν σύνολα δεδομένων από διαφορετικές χώρες. Αυτό δημιουργεί νέες δυνατότητες για την ανάπτυξη καινοτόμων υπηρεσιών και εφαρμογών.
Ταυτόχρονα, δίνεται ιδιαίτερη έμφαση στην ασφάλεια και την προστασία των δεδομένων, διασφαλίζοντας ότι οι πληροφορίες διακινούνται με τρόπο αξιόπιστο και σύμφωνο με τις ευρωπαϊκές απαιτήσεις προστασίας προσωπικών δεδομένων. Αυτό είναι καθοριστικό για την ενίσχυση της εμπιστοσύνης των πολιτών προς τις ψηφιακές δημόσιες υπηρεσίες.
Συνολικά, τα Ψηφιακά Δομικά Στοιχεία για την Ευρώπη αποτελούν έναν θεμελιώδη πυλώνα για την οικοδόμηση ενός ενιαίου ψηφιακού χώρου, όπου οι δημόσιες υπηρεσίες είναι πιο αποδοτικές, προσβάσιμες και διασυνδεδεμένες. Με την αξιοποίησή τους, οι δημόσιοι οργανισμοί και οι επιχειρήσεις μπορούν να επιταχύνουν την ψηφιακή τους μετάβαση και να προσφέρουν καλύτερες υπηρεσίες στους πολίτες σε όλη την Ευρώπη.
Η παγκόσμια κοινότητα της κυβερνοασφάλειας βρίσκεται μπροστά σε μια κρίσιμη καμπή. Οι εξελίξεις στους κβαντικούς υπολογιστές επιταχύνουν δραματικά τα χρονοδιαγράμματα για την αναβάθμιση των συστημάτων κρυπτογράφησης. Πρόσφατες εκτιμήσεις μεταθέτουν την προθεσμία για την «κβαντική ετοιμότητα» ήδη στο 2029 — πολύ νωρίτερα απ’ ό,τι αναμενόταν μέχρι πρόσφατα.
Αυτή η κατάσταση θυμίζει σε πολλούς το περίφημο πρόβλημα του Y2K, όταν υπήρχε ο φόβος ότι τα υπολογιστικά συστήματα θα κατέρρεαν με την αλλαγή της χιλιετίας. Ωστόσο, η σημερινή πρόκληση είναι πιο σύνθετη και, σε ορισμένες πτυχές, πιο επικίνδυνη.
Δύο βασικές απειλές
Η πρώτη απειλή αφορά το μέλλον: όταν οι κβαντικοί υπολογιστές αποκτήσουν επαρκή ισχύ, θα μπορούν να «σπάνε» τα σημερινά συστήματα δημόσιου κλειδιού. Αυτό σημαίνει ότι επιτιθέμενοι θα μπορούν να πλαστογραφούν ταυτότητες, να παρακάμπτουν μηχανισμούς πιστοποίησης και να εισάγουν κακόβουλο λογισμικό με σχετική ευκολία.
Η δεύτερη απειλή είναι ήδη εδώ και θεωρείται ακόμη πιο ανησυχητική: το λεγόμενο «store now, decrypt later». Δηλαδή, κάποιος μπορεί σήμερα να αποθηκεύει κρυπτογραφημένες επικοινωνίες και, στο μέλλον, όταν οι κβαντικοί υπολογιστές γίνουν αρκετά ισχυροί, να τις αποκρυπτογραφήσει. Αυτό σημαίνει ότι δεδομένα που θεωρούνται ασφαλή σήμερα ενδέχεται να εκτεθούν αύριο.
Τι παραμένει ασφαλές;
Δεν είναι όλα τα συστήματα ευάλωτα. Η συμμετρική κρυπτογράφηση —όπως αυτή που χρησιμοποιείται για την κρυπτογράφηση δίσκων— θεωρείται ανθεκτική απέναντι σε κβαντικές επιθέσεις, εφόσον χρησιμοποιούνται επαρκώς μεγάλα κλειδιά. Το πρόβλημα, όμως, εντοπίζεται κυρίως στη διανομή αυτών των κλειδιών και στους μηχανισμούς πιστοποίησης.
Η ανάγκη για μετάβαση σε μετα-κβαντική κρυπτογραφία
Η λύση βρίσκεται στη μετάβαση σε νέους αλγορίθμους, γνωστούς ως «post-quantum» ή μετα-κβαντικούς. Οι σχετικές προδιαγραφές έχουν ήδη οριστικοποιηθεί από διεθνείς οργανισμούς, και πολλές μεγάλες πλατφόρμες έχουν αρχίσει να τις υιοθετούν.
Παρόλα αυτά, η μετάβαση δεν είναι απλή. Απαιτεί εκτεταμένες αλλαγές σε υποδομές, λογισμικό και υλικό. Ορισμένες τεχνολογίες, ιδιαίτερα εκείνες που βασίζονται σε παλαιότερο εξοπλισμό ή έχουν ενσωματωμένα πιστοποιητικά, ενδέχεται να μην προλάβουν να προσαρμοστούν εγκαίρως.
Ο ρόλος των μηχανικών και των εταιρειών
Οι επαγγελματίες του χώρου καλούνται να δράσουν άμεσα. Η αναβάθμιση των συστημάτων ανταλλαγής κλειδιών και η ενίσχυση των μηχανισμών πιστοποίησης είναι πλέον επιτακτική ανάγκη. Παράλληλα, οι εταιρείες πρέπει να παρακολουθούν τις εξελίξεις και να ενσωματώνουν τις νέες τεχνολογίες μόλις αυτές γίνονται διαθέσιμες.
Ωστόσο, η εξάρτηση από τρίτους παρόχους (π.χ. λογισμικό ή υποδομές cloud) μπορεί να καθυστερήσει τη διαδικασία, καθώς η μετάβαση απαιτεί συντονισμένες ενέργειες σε πολλά επίπεδα.
Τι μπορούν να κάνουν οι απλοί χρήστες
Αν και οι τεχνικές λεπτομέρειες μπορεί να φαίνονται μακρινές, οι χρήστες έχουν επίσης ρόλο να παίξουν:
Να ενημερώνουν τακτικά τις συσκευές και τις εφαρμογές τους
Να επιλέγουν υπηρεσίες που έχουν ήδη ανακοινώσει υποστήριξη για μετα-κβαντική ασφάλεια
Να είναι πιο προσεκτικοί με το τι μοιράζονται διαδικτυακά
Ειδικά στις εφαρμογές επικοινωνίας, είναι σημαντικό να γνωρίζουμε αν τα δεδομένα προστατεύονται και μελλοντικά — όχι μόνο σήμερα.
Προκλήσεις και περιορισμοί
Ορισμένες τεχνολογίες, όπως τα Trusted Execution Environments (TEE), ενδέχεται να μην προσαρμοστούν εγκαίρως. Παρότι προσφέρουν ένα επίπεδο προστασίας, στην εποχή των κβαντικών υπολογιστών η ασφάλειά τους μειώνεται σημαντικά.
Επιπλέον, λειτουργίες όπως η ανάλυση συνομιλιών μέσω τεχνητής νοημοσύνης ή η αυτόματη σύνοψη μηνυμάτων ενδέχεται να αυξήσουν τον κίνδυνο διαρροής ευαίσθητων δεδομένων.
Πόσο έτοιμος είναι ο κόσμος;
Η πρόοδος είναι ήδη αισθητή. Ένα σημαντικό ποσοστό ιστοσελίδων υποστηρίζει πλέον μετα-κβαντικούς μηχανισμούς, ενώ νέες συσκευές αρχίζουν να ενσωματώνουν σχετικές τεχνολογίες.
Παρόλα αυτά, η πλήρης μετάβαση μέχρι το 2029 παραμένει αμφίβολη. Όπως και σε προηγούμενες αλλαγές (π.χ. η κατάργηση του SHA-1), ορισμένοι τομείς θα καθυστερήσουν σημαντικά.
Η μετάβαση στη μετα-κβαντική κρυπτογραφία δεν είναι απλώς μια τεχνική αναβάθμιση — είναι μια παγκόσμια πρόκληση με τεράστιες επιπτώσεις στην ιδιωτικότητα και την ασφάλεια.
Η διαφορά με το Y2K δεν είναι μόνο χρονική, αλλά και ποιοτική: αυτή τη φορά, το διακύβευμα δεν είναι αν τα συστήματα θα συνεχίσουν να λειτουργούν, αλλά αν τα δεδομένα μας θα παραμείνουν πραγματικά ασφαλή — σήμερα και στο μέλλον.
Στον σύγχρονο κόσμο της διεθνούς εκπαίδευσης και της επαγγελματικής κινητικότητας, η αναγνώριση των προσόντων ενός ατόμου συχνά αποτελεί πρόκληση. Διαφορετικά εκπαιδευτικά συστήματα, γλώσσες και πρότυπα αξιολόγησης δυσκολεύουν τη σαφή και αξιόπιστη κατανόηση των δεξιοτήτων και των γνώσεων ενός ατόμου. Για να αντιμετωπιστεί αυτό το πρόβλημα, η Ευρωπαϊκή Επιτροπή ανέπτυξε το Ευρωπαϊκό Μοντέλο Μάθησης (European Learning Model – ELM), ένα καινοτόμο πλαίσιο που λειτουργεί ως «κοινή γλώσσα» για την περιγραφή εκπαιδευτικών επιτευγμάτων.
Το ELM αποτελεί τη βάση για μια σειρά από πρότυπα και ορισμούς που επιτρέπουν την καταγραφή ολόκληρης της εκπαιδευτικής πορείας ενός ατόμου. Από πανεπιστημιακά πτυχία μέχρι επαγγελματικές πιστοποιήσεις, το σύστημα αυτό εξασφαλίζει ότι τα προσόντα που αποκτώνται σε μία χώρα μπορούν να γίνουν κατανοητά και αποδεκτά σε μια άλλη. Με αυτόν τον τρόπο ενισχύεται η διαφάνεια, η συγκρισιμότητα και η κινητικότητα εργαζομένων και φοιτητών εντός και εκτός Ευρώπης.
Ένα βασικό χαρακτηριστικό του εγχειρήματος είναι η έμφαση στο ανοικτό λογισμικό. Μέσω της πλατφόρμας code.europa.eu, η Ευρωπαϊκή Επιτροπή διαθέτει εργαλεία που βασίζονται στο ELM, επιτρέποντας σε οργανισμούς να τα επαναχρησιμοποιήσουν και να τα ενσωματώσουν στα δικά τους συστήματα. Αυτή η προσέγγιση ενισχύει τη διαλειτουργικότητα και διευκολύνει τη συνεργασία μεταξύ διαφορετικών φορέων εκπαίδευσης και κατάρτισης.
Ανάμεσα στα βασικά εργαλεία που έχουν αναπτυχθεί ξεχωρίζουν τα Ευρωπαϊκά Ψηφιακά Διαπιστευτήρια για τη Μάθηση (European Digital Credentials – EDC). Τα EDC επιτρέπουν την ασφαλή, άμεση και ψηφιακή επιβεβαίωση προσόντων, αντικαθιστώντας τις παραδοσιακές, χρονοβόρες διαδικασίες ανταλλαγής εγγράφων. Ένας απόφοιτος μπορεί πλέον να αποδείξει τις δεξιότητές του σε έναν εργοδότη σε άλλη χώρα με τρόπο γρήγορο και αξιόπιστο, διευκολύνοντας σημαντικά την πρόσβαση στην αγορά εργασίας.
Παράλληλα, το Qualifications Dataset Register (QDR) λειτουργεί ως εργαλείο ανταλλαγής δεδομένων για προσόντα μεταξύ κρατών και οργανισμών. Η διάθεσή του ως ανοικτού λογισμικού έχει επεκτείνει τη χρήση του πέρα από την Ευρώπη, ενισχύοντας τη διεθνή συνεργασία, ακόμη και σε περιοχές όπως η Αφρική και η Κεντρική Ασία.
Ωστόσο, η πρωτοβουλία αυτή δεν στοχεύει στη δημιουργία μιας μεγάλης κοινότητας προγραμματιστών, όπως συμβαίνει σε άλλα έργα ανοικτού λογισμικού. Αντίθετα, δίνεται έμφαση στη διαφάνεια και στη δυνατότητα ενσωμάτωσης των εργαλείων από μεγάλους οργανισμούς και ιδρύματα. Το σημαντικό είναι ότι οι ενδιαφερόμενοι μπορούν να παρακολουθούν την εξέλιξη του συστήματος και να αξιοποιούν τις δυνατότητές του σύμφωνα με τις ανάγκες τους.
Το μέλλον του ELM συνδέεται άμεσα με νέες πρωτοβουλίες, όπως η ενίσχυση της φορητότητας δεξιοτήτων (Skills Portability), που θα επιτρέψει ακόμη μεγαλύτερη διαλειτουργικότητα μεταξύ ψηφιακών εργαλείων. Με τη συνεχή ανάπτυξη και τη διάθεση των εργαλείων υπό την άδεια ανοικτού λογισμικού της Ευρωπαϊκής Ένωσης (EUPL), το έργο συμβάλλει ενεργά στον ψηφιακό μετασχηματισμό της εκπαίδευσης και της κατάρτισης.
Συνολικά, το Ευρωπαϊκό Μοντέλο Μάθησης και τα συναφή εργαλεία αποτελούν ένα σημαντικό βήμα προς μια πιο ενιαία, διαφανή και προσβάσιμη αγορά γνώσης και εργασίας. Μέσα από τη δύναμη του ανοικτού λογισμικού, η Ευρώπη δημιουργεί τις προϋποθέσεις για ένα μέλλον όπου τα προσόντα κάθε ατόμου αναγνωρίζονται χωρίς σύνορα.
In a keynote presentation at the 2026 Mining Software Repositories
Emerson Murphy-Hill, a star researcher at Microsoft, presented his
view on the role of an empirical software engineering researcher in the age of generative AI.
His talk focused on three themes: the durability, differentiation, and
dissemination of research.
Οι ψεύτικες αναφορές ασφαλείας που παράγουν AI chatbots πλημμυρίζουν τα open source projects. Πώς μοιάζουν και τι κάνουν οι προγραμματιστές γι'αυτό;
Φαντάσου να ξυπνάς ένα πρωί Δευτέρα, να ανοίγεις το email σου και να βρίσκεις επτά αναφορές ασφαλείας που σε περιμένουν. Ήρθαν μέσα σε 16 ώρες. Η καρδιά σου σφίγγεται - το project σου τρέχει σε δισεκατομμύρια συσκευές σε όλο τον κόσμο. Αφιερώνεις ολόκληρη την ημέρα σου να διαβάζεις, να αξιολογείς, να επικοινωνείς με τους reporters. Και στο τέλος; Κανένα από τα επτά δεν ήταν πραγματικό πρόβλημα.
Αυτό δεν είναι σενάριο επιστημονικής φαντασίας. Συνέβη στον Daniel Stenberg, δημιουργό του curl - του εργαλείου που χρησιμοποιείται σε περίπου 20-30 δισεκατομμύρια εγκαταστάσεις και τρέχει, κυριολεκτικά, παντού: από το iPhone σου ως τα Samsung smart TV και τα αεροπλάνα. Στο FOSDEM 2026 στις Βρυξέλλες, ο Stenberg μίλησε για το φαινόμενο που ονόμασε "AI slop reporting" — τη μαζική αποστολή πλαστών αναφορών ασφαλείας που παράγουν chatbots AI, χωρίς καμία επαλήθευση από τον άνθρωπο που τις υποβάλλει.
Το αποτέλεσμα; Το curl ανέστειλε το bug bounty πρόγραμμά του τον Φεβρουάριο του 2026 — ένα πρόγραμμα που είχε πληρώσει πάνω από 92.000 δολάρια σε 81 πραγματικά ευρήματα ασφαλείας σε έξι χρόνια. Η αιτία: η αναλογία αληθινών reports έπεσε από 1 στα 6 σε 1 στα 20–30.
Αλλά η ιστορία δεν αφορά μόνο το curl. Το ίδιο φαινόμενο έχει παρατηρηθεί στην Python, στο Mesa Project, στο Open Collective και σε δεκάδες άλλα open source projects. Και το ερώτημα που γεννάται είναι πρακτικό: πώς μοιάζει ένα AI-generated security report; Πώς μπορείς να το αναγνωρίσεις — είτε ως συντηρητής είτε ως απλός χρήστης που θέλει να καταλαβαίνει τι συμβαίνει στα tools που χρησιμοποιεί;
Γιατί κάποιος στέλνει πλαστές αναφορές ασφαλείας;
Η απάντηση είναι στρωτή: τα bug bounty προγράμματα. Το curl προσέφερε έως $10.000 για ένα critical εύρημα και $500 για ένα low-severity. Με ένα LLM chatbot, το κόστος για να παράγεις μια εντυπωσιακά "τεχνική" αναφορά είναι μηδέν. Ο χρόνος που απαιτείται; Δευτερόλεπτα.
Ο Stenberg το συγκρίνει με το spam email: αν ένα στα εκατομμύρια μηνύματα αποφέρει κάτι, αξίζει να στείλεις δύο εκατομμύρια. Εδώ, αν ένα report από τα δέκα "περάσει" και αποφέρει $500, ο "επενδυτής" με τα chatbots βγαίνει μπροστά. Το πρόβλημα είναι ότι το κόστος το πληρώνουν οι εθελοντές συντηρητές με ώρες ζωής, ενέργεια και ψυχική υγεία.
📌 Σημαντικό: Ο Stenberg τόνισε ότι το πρόβλημα δεν είναι η τεχνολογία AI. Είναι ο άνθρωπος που επιλέγει να μην επαληθεύει αυτό που του δίνει το chatbot πριν το υποβάλει. "Δεν μπορώ να φτιάξω τους ανθρώπους, ούτε καν με AI," είπε χαρακτηριστικά στο FOSDEM.
10 σημάδια ότι μια αναφορά ασφαλείας φτιάχτηκε από Chatbot
Βασισμένα στην εμπειρία του Stenberg και σε ευρύτερη έρευνα από την κοινότητα του open source, αυτά είναι τα πιο αξιόπιστα σημάδια:
1. Υπερβολικά ευγενική γλώσσα στην αρχή
Ο Stenberg το είπε αστεία αλλά ακριβώς: "Κανένας άνθρωπος δεν ξεκίνησε ποτέ ένα security report με 'I apologize, but I found a problem.'" Οι πραγματικοί ερευνητές ασφαλείας τείνουν να είναι άμεσοι — μερικές φορές και αγενείς. Ένα report που ανοίγει με εκτενείς ευχαριστίες, αναγνώριση της προσπάθειας της ομάδας και χαμηλόφωνη "επισήμανση" μοιάζει περισσότερο με AI output παρά με αυθεντική ανακάλυψη.
2. Τέλεια αγγλικά χωρίς κανένα τυπογραφικό λάθος
Οι άνθρωποι κάνουν λάθη. Ιδιαίτερα σε τεχνικά κείμενα που γράφονται σε δεύτερη γλώσσα. Ένα report χωρίς ούτε ένα typo, με άψογη σύνταξη και γραμματική καθ' όλη τη διάρκειά του, είναι ασυνήθιστο για αυθεντική ανθρώπινη γραφή, ειδικά σε ένα υποβολή στο HackerOne στις 2 το πρωί.
3. Mixed Case τίτλος "Για Να Φαίνεται Σοβαρό"
Οι τίτλοι των πλαστών reports συχνά γράφονται με κεφαλαία σε κάθε λέξη. "Critical Memory Corruption Vulnerability In HTTP/3 Stack". Μια συνήθεια που τα LLMs έχουν υιοθετήσει από τεχνικά άρθρα και CVE databases. Κανένας άνθρωπος δεν γράφει έτσι φυσικά.
4. Απίθανο μήκος, χιλιάδες λέξεις χωρίς ουσία
Παλιά, ένας maintainer παρακαλούσε τους reporters: "Μπορείτε να μου δώσετε λίγο περισσότερες λεπτομέρειες;" Τώρα το πρόβλημα είναι το αντίθετο. Ο Stenberg λέει ότι τα AI reports έχουν γίνει τόσο μακροσκελή που πλέον ζητά: "Μπορείς να μου εξηγήσεις αυτό σε 10 γραμμές ή λιγότερες;" Αν δεν το κάνει, λαμβάνει 200 ακόμη γραμμές στην επόμενη απάντηση.
5. Bullet point bonanza. Τριάδες παντού
Κάθε παράγραφος ακολουθείται από ακριβώς τρία bullet points. Μετά άλλα τρία. Και άλλα τρία. Ο Stenberg το παρατήρησε επανειλημμένα: "Ένας άνθρωπος δεν γράφει 12 παραγράφους, η καθεμία με ακριβώς τρία bullet points." Αυτό είναι AI formatting, όχι ανθρώπινη γραφή.
6. Emojis μέσα σε τεχνικά παραδείγματα κώδικα
Αν βλέπεις emojis ενσωματωμένα σε code snippets ή σε τεχνική τεκμηρίωση ασφαλείας, κάτι δεν πάει καλά. Τα LLMs έχουν εκπαιδευτεί σε τεράστια ποσότητα περιεχομένου από το ίντερνετ, συμπεριλαμβανομένων άρθρων με emojis, και μερικές φορές αυτά "διαρρέουν" σε τεχνικό κώδικα με τρόπο που κανένας έμπειρος developer δεν θα έκανε.
7. "You're absolutely right" στις follow-up απαντήσεις
Όταν ο Stenberg ρωτούσε follow-up ερώτηση, έπαιρνε πάντα κάτι σαν: "You're absolutely right. I apologize for the confusion." Κι ύστερα μια νέα, ακόμη μεγαλύτερη απάντηση που συχνά έχανε το νήμα της αρχικής συζήτησης. Οι chatbots συμφωνούν με τον συνομιλητή τους. Δεν αντιδρούν με την αυτοπεποίθηση ενός ερευνητή που γνωρίζει τι ανακάλυψε.
8. Πλαστές τεχνικές αποδείξεις (fake GDB sessions, κώδικας που δεν κάνει compile)
Αυτό είναι το πιο επικίνδυνο σημείο, γιατί είναι και το πιο δύσκολο να εντοπιστεί. Ο Stenberg περιέγραψε στο FOSDEM ένα report για ένα "HTTP/3 stream dependency cycle exploit" που ήρθε πλήρες με GDB sessions, register dumps και proof-of-concept κώδικα. Έδειχνε πολύ αληθινό. Αλλά η συνάρτηση στην οποία αναφερόταν το report δεν υπάρχει στο curl. Το GDB session ήταν εξ ολοκλήρου επινοημένο. Τα register contents ήταν λάθος. Τίποτα από αυτά δεν συνέβη ποτέ.
9. Όλα είναι "CRITICAL", ακόμη και τα ασήμαντα
Όταν υπάρχει bug bounty με $10.000 για critical ευρήματα, τι κάνει ένα AI που δεν γνωρίζει πραγματικό severity; Βάζει "CRITICAL" παντού. Ο Stenberg παρατήρησε ότι σχεδόν κάθε πλαστό report έφτανε ως critical, ακόμα και αν αφορούσε κάτι εντελώς αθώο, όπως το γεγονός ότι το Git repository του project είναι… δημοσίως ορατό στο internet (κάτι που είναι, φυσικά, απολύτως σκόπιμο).
10. Αναφορά σε χαρακτηριστικά ή εκδόσεις που δεν υπάρχουν
Τα LLMs hallucinate δηλαδή "εφευρίσκουν" πληροφορίες που φαίνονται αληθινές αλλά δεν είναι. Στα security reports αυτό εκδηλώνεται ως αναφορές σε functions που δεν υπάρχουν στον κώδικα, changelogs που δεν αντιστοιχούν στην πραγματικότητα, ή code snippets που δεν θα έκαναν compile ποτέ. Το curl security team έλαβε report με κώδικα curl_easy_setopt με λάθος signature, κώδικας που απλά δεν θα δούλευε.
Το πρόβλημα εξελίσσεται και γίνεται πιο δύσκολο να εντοπιστεί
Αν νομίζεις ότι αρκεί να ψάχνεις για τα παραπάνω σημάδια για να είσαι ασφαλής, υπάρχουν νέες εξελίξεις που περιπλέκουν τα πράγματα.
Πρώτον, τα ίδια τα AI models βελτιώνονται συνεχώς. Ο Stenberg παρατήρησε ότι τα reports του 2026 δεν μοιάζουν ακριβώς με αυτά του 2025. Τα LLMs μαθαίνουν να αποφεύγουν τα γνωστά "τελικά σημάδια". Δεύτερον, κάποιοι reporters ξεκίνησαν να επαναγράφουν τα AI outputs με το χέρι, για να αφαιρέσουν τα χαρακτηριστικά τεκμήρια AI-γραφής. Αποτέλεσμα: reports που δεν ακούγονται σαν AI, αλλά εξακολουθούν να βασίζονται σε hallucinated πληροφορίες.
Τρίτον, υπάρχει πλέον μια "νέα γενιά ηλιθιότητας", όπως την αποκάλεσε ο Stenberg. Ορισμένοι χρησιμοποιούν AI για να βρουν τι να αναφέρουν, αλλά το γράφουν μόνοι τους. Αποτέλεσμα: reports που αναφέρουν πράγματα όπως "βρήκα ότι το Git repository σου είναι δημοσίως ορατό", μια "αποκάλυψη" που για κάθε open source project είναι απολύτως σκόπιμη.
"Μεταξύ 30% και 70% των submissions που λάβαμε στα τέλη του 2025 και στις αρχές του 2026 ήταν AI-generated. Δυο χρόνια πριν, δεν υπήρχε τίποτα τέτοιο."
Γιατί έχει σημασία. Πέρα από το curl
Μπορεί να αναρωτιέσαι: "Και τι με νοιάζει εμένα; Δεν συντηρώ open source software." Η απάντηση είναι απλή: χρησιμοποιείς open source software. Το curl τρέχει στο κινητό σου, στο laptop σου, στις εφαρμογές που ανοίγεις κάθε μέρα. Η Python εκτελεί εκατομμύρια web services. Το OpenSSL κρυπτογραφεί τις online συναλλαγές σου.
Όταν ένας μικρός αριθμός εθελοντών, η ομάδα ασφαλείας του curl αποτελείται από επτά άτομα, ξοδεύει τον χρόνο του να αξιολογεί εκατοντάδες πλαστά reports, αυτό έχει συνέπειες:
Μειωμένη προσοχή στα πραγματικά προβλήματα: Ο "θόρυβος" δημιουργεί fatigue. Υπάρχει ο κίνδυνος ένα πραγματικό critical vulnerability να χαθεί ανάμεσα σε 30 πλαστά.
Burnout: Το open source είναι ήδη ένας χώρος με υψηλά επίπεδα εξουθένωσης. Η πρόσθεση εκατοντάδων ωρών σε ανούσιο triage επιδεινώνει ένα ήδη σοβαρό πρόβλημα.
Supply chain risks: Ο Stenberg το είπε ξεκάθαρα: αν η ποιότητα του project υποφέρει λόγω εξουθένωσης, αυτό γίνεται πρόβλημα για όλους όσους εξαρτώνται από αυτό.
Τι κάνουν τα Projects. Τι μπορείς να κάνεις εσύ
Τα open source projects δοκιμάζουν διάφορες στρατηγικές για να αντιμετωπίσουν το πρόβλημα, με διαφορετικά αποτελέσματα:
Στρατηγική
Αποτέλεσμα
Μειονέκτημα
Checkbox "χρησιμοποίησες AI;"
Δούλεψε 3-4 φορές
Οι reporters απλά λένε "όχι"
Ban reporters
Άμεση αντίδραση
Νέος λογαριασμός σε λεπτά
Public shaming των πλαστών reports
Κάποια αποτρεπτική επίδραση
Επηρεάζει τους "καλούς" reporters
Κατάργηση bug bounty (curl)
Αφαιρεί οικονομικό κίνητρο
Αποθαρρύνει και νόμιμους ερευνητές
Raised reputation requirements
Μειώνει new entrants
Κλείνει πόρτες σε νέους ερευνητές
Καμία από αυτές τις λύσεις δεν είναι τέλεια. Ο Stenberg το παρομοίασε με το spam των emails: "Έχουμε μια λύση για το spam. Δεν δουλεύει, αλλά τουλάχιστον κάτι κάναμε."
Αν εσύ θέλεις να κάνεις ένα αυθεντικό security report σε ένα open source project, η καλύτερη συμβουλή είναι:
Επαλήθευσε ό,τι σου δίνει το AI: τρέξε τον κώδικα, δες αν η συνάρτηση υπάρχει στην πραγματικότητα.
Γράψε σύντομα και συγκεκριμένα: αν δεν μπορείς να εξηγήσεις το πρόβλημα σε 5-10 γραμμές, πιθανώς δεν το καταλαβαίνεις.
Χρησιμοποίησε την έκδοση που τρέχεις εσύ: μην αναφέρεις εκδόσεις που δεν έχεις δοκιμάσει.
Δώσε reproduction steps που δουλεύουν: αν δεν μπορείς να αναπαράγεις το πρόβλημα μόνος σου, δεν είσαι έτοιμος να το αναφέρεις.
Η άλλη πλευρά: Το AI μπορεί να βρει πραγματικά Bugs
Ο Stenberg, δεν είναι κατά του AI ως τεχνολογία. Και εδώ βρίσκεται η ουσιαστική διαφορά που αξίζει να κατανοήσουμε.
Το curl χρησιμοποιεί πλέον AI-powered εργαλεία ανάλυσης κώδικα εσωτερικά. Από τότε που ξεκίνησαν, ο Stenberg έχει διορθώσει πάνω από 100 bugs που εντόπισαν αυτά τα εργαλεία, bugs που κανένα από τα παλαιότερα, παραδοσιακά εργαλεία δεν είχε βρει. Τον Σεπτέμβριο του 2025, ένας ερευνητής ασφαλείας βασισμένος στην Πολωνία, ο Joshua Rogers, χρησιμοποίησε AI scanning tools με τον σωστό τρόπο, με ανθρώπινη εμπειρία και επαλήθευση, και εντόπισε δεκάδες πραγματικά προβλήματα στο curl.
Η διαφορά μεταξύ χρήσιμης και επιβλαβούς χρήσης του AI σε security research δεν είναι στην τεχνολογία. Είναι στον έμπειρο άνθρωπο που ξέρει να αξιολογεί τα αποτελέσματα, να απορρίπτει τα false positives και να επαληθεύει ότι ένα εύρημα είναι πραγματικό πριν το υποβάλει.
🔑 Το κλειδί
Ένα AI tool που βρίσκει πιθανά προβλήματα είναι ένα σημείο εκκίνησης, όχι ένα έτοιμο security report. Ο ανθρώπινος έλεγχος, η επαλήθευση και η κατανόηση του κώδικα δεν μπορούν να παραλειφθούν, και αυτός ακριβώς ο παραλειπόμενος έλεγχος είναι που κάνει τη διαφορά ανάμεσα σε ένα χρήσιμο εύρημα και σε "AI slop".
Συμπέρασμα
Το open source ecosystem είναι η υποδομή του σύγχρονου internet, και η ασφάλειά του εξαρτάται σε μεγάλο βαθμό από εθελοντές που δουλεύουν με περιορισμένους πόρους. Η πλημμύρα πλαστών AI-generated security reports δεν είναι απλώς ένα τεχνικό αστείο. Είναι ένα πρόβλημα που μπορεί να έχει πραγματικές συνέπειες στο λογισμικό που χρησιμοποιείς καθημερινά.
Το να αναγνωρίζεις τα σημάδια ενός πλαστού report, είτε ως συντηρητής είτε ως χρήστης που παρακολουθεί τα νέα της κοινότητας, είναι μικρό αλλά σημαντικό βήμα για να καταλαβαίνεις τι πραγματικά συμβαίνει στα εργαλεία που εμπιστεύεσαι.
Και αν ποτέ θελήσεις να αναφέρεις ένα security issue σε ένα open source project, δοκίμασέ το πρώτα. Επαλήθευσέ το. Γράψ' το με τα δικά σου λόγια. Και σεβάσου τον χρόνο των ανθρώπων που κρατούν αυτά τα projects ζωντανά.
Όταν η Τεχνητή Νοημοσύνη παύει να περιμένει εντολές
Για χρόνια, η δημόσια συζήτηση για την Τεχνητή Νοημοσύνη περιστρεφόταν γύρω από έναν ψηφιακό βοηθό που απαντά σε ερωτήσεις, συνοψίζει έγγραφα ή προτείνει κείμενα. Αυτή η εικόνα είναι ήδη ξεπερασμένη. Το πραγματικό διακύβευμα αρχίζει όταν η ΤΝ παύει να περιμένει εντολές και αποκτά μόνιμη παρουσία, πρόσβαση σε εργαλεία, σύνδεση με εξωτερικά γεγονότα και δυνατότητα να δρα ενώ ο άνθρωπος λείπει. Από εκεί και πέρα δεν μιλάμε για ένα απλό λογισμικό παραγωγικότητας. Μιλάμε για μια υποδομή που εισάγει νέο επίπεδο λειτουργικού, θεσμικού και πολιτικού κινδύνου.
Ένας τέτοιος πράκτορας, όταν έχει πρόσβαση σε προσωπικά δεδομένα πολιτών, σε κυβερνητικά πληροφοριακά συστήματα ή σε ευαίσθητες πολιτικές πληροφορίες, δεν είναι απλώς ένα ισχυρό εργαλείο. Είναι ένα νέο σημείο συγκέντρωσης εξουσίας. Κρατά μνήμη, συσχετίζει πληροφορίες από πολλαπλές πηγές, μετατρέπει φυσική γλώσσα σε εντολές, αποκτά ρόλο διαμεσολαβητή ανάμεσα στον δημόσιο λειτουργό και στο σύστημα. Όσο πιο διακριτικά ενσωματώνεται στη ροή εργασίας, τόσο πιο εύκολο είναι να θεωρηθεί φυσιολογικό να του παραχωρούνται όλο και περισσότερα δικαιώματα. Ακριβώς εκεί αρχίζει το πρόβλημα.
Το πρόβλημα δεν είναι μόνο τι ξέρει, αλλά τι μπορεί να κάνει
Η παραδοσιακή ασφάλεια πληροφοριών σχεδιάστηκε γύρω από χρήστες, εφαρμογές και σαφώς οριοθετημένα δικαιώματα. Ο αυτόνομος πράκτορας θολώνει αυτά τα όρια. Δεν βλέπει μόνο πληροφορία, αλλά αποφασίζει πώς θα τη χρησιμοποιήσει. Δεν ανοίγει απλώς ένα αρχείο, αλλά μπορεί να το συσχετίσει με ένα μήνυμα, μια ιστοσελίδα, ένα εσωτερικό υπόμνημα, ένα ημερολόγιο, μια εντολή σε τερματικό ή μια κλήση διεπαφής προγραμματισμού. Αυτό σημαίνει ότι η επιφάνεια επίθεσης μεγαλώνει κατακόρυφα.
Η πιο επικίνδυνη ψευδαίσθηση είναι ότι αρκεί να ορίσουμε δικαιώματα πρόσβασης και το πρόβλημα λύθηκε. Δεν λύθηκε. Ένας πράκτορας που έχει άδεια να διαβάζει, να ταξινομεί, να αναζητά, να πλοηγείται και να ενεργοποιείται από εξωτερικά συμβάντα μπορεί να γίνει αγωγός εξαγωγής δεδομένων, να υποστεί κακόβουλη έγχυση οδηγιών, να παραπλανηθεί από ένα έγγραφο, μια ιστοσελίδα ή ένα ηλεκτρονικό μήνυμα και να μετατρέψει ένα φαινομενικά αθώο ερέθισμα σε αλληλουχία ενεργειών με πραγματικές συνέπειες. Το πρόβλημα, λοιπόν, δεν είναι μόνο η διαρροή. Είναι η μεταφορά πρωτοβουλίας από τον άνθρωπο στο σύστημα.
Σε ένα υπουργείο, σε μια ρυθμιστική αρχή ή σε ένα γραφείο που επεξεργάζεται ευαίσθητες πολιτικές αποφάσεις, αυτός ο κίνδυνος είναι ακόμη πιο σοβαρός. Ο πράκτορας δεν εκτίθεται μόνο σε δεδομένα. Εκτίθεται σε προθέσεις, διαπραγματευτικές θέσεις, σχέδια νόμου, πολιτικά σενάρια, ατελείς εισηγήσεις, εσωτερικές διαφωνίες. Δηλαδή εκτίθεται σε υλικό που αποκτά αξία ακριβώς επειδή δεν είναι δημόσιο. Αν ένα τέτοιο σύστημα είναι κλειστό, μη ελέγξιμο και εξαρτημένο από έναν προμηθευτή, τότε η δημόσια διοίκηση παραχωρεί όχι μόνο λειτουργίες αλλά και γνωσιακή κυριαρχία.
Το μάθημα από τη διαρροή του Claude Code
Η πρόσφατη διαρροή πηγαίου κώδικα του Claude Code έκανε ορατό κάτι που συχνά μένει αόρατο στους χρήστες και στους οργανισμούς: σε κλειστά συστήματα μπορεί να υπάρχουν δυνατότητες, διακόπτες λειτουργιών και επιλογές συμπεριφοράς που το κοινό, οι πελάτες και συχνά ακόμη και οι διαχειριστές δεν γνωρίζουν. Το γεγονός ότι αποκαλύφθηκαν 44 κρυφοί διακόπτες λειτουργιών δεν είναι απλώς τεχνική λεπτομέρεια. Είναι μάθημα διακυβέρνησης. Δείχνει τι σημαίνει να βασίζεσαι σε ένα κρίσιμο ψηφιακό σύστημα χωρίς τη δυνατότητα ουσιαστικού δημόσιου ελέγχου.
Σε ένα έργο ανοιχτού κώδικα, τέτοια στοιχεία δεν θα παρέμεναν αόρατα για πολύ. Αυτό δεν σημαίνει ότι ο ανοιχτός κώδικας είναι μαγική ασπίδα. Σημαίνει κάτι πιο ουσιαστικό και πιο ώριμο: επιτρέπει ανεξάρτητο έλεγχο, επαλήθευση, ανίχνευση ευπαθειών, δημόσια συζήτηση για τον σχεδιασμό και συλλογική βελτίωση. Με άλλα λόγια, μειώνει το πεδίο του άγνωστου. Και στην ασφάλεια, το άγνωστο είναι συχνά πιο επικίνδυνο από το γνωστό ελάττωμα.
Ανοιχτότητα, λογοδοσία και ανθρώπινος έλεγχος
Για το Δημόσιο, η σωστή αρχή δεν είναι να απαγορεύσει την ΤΝ, αλλά να απαγορεύσει την αδιαφανή αυτονομία της ΤΝ σε κρίσιμα πεδία. Κάθε πράκτορας που έχει πρόσβαση σε προσωπικά δεδομένα, διοικητικές πράξεις ή ευαίσθητες πολιτικές πληροφορίες πρέπει να λειτουργεί με ελάχιστα αναγκαία δικαιώματα, πλήρη καταγραφή ενεργειών, υποχρεωτικά σημεία ανθρώπινης έγκρισης και, όπου είναι δυνατόν, με ανοιχτό κώδικα ή τουλάχιστον με πλήρη ελεγκτική δυνατότητα από ανεξάρτητους φορείς.
Ηαρχή πρέπει να είναι απλή. Όσο αυξάνεται η αυτονομία, τόσο πρέπει να αυξάνεται η διαφάνεια. Όσο αυξάνεται η πρόσβαση, τόσο πρέπει να αυξάνεται η λογοδοσία. Όσο πιο κρίσιμο είναι το περιβάλλον χρήσης, τόσο λιγότερο ανεκτό είναι το μαύρο κουτί. Ένας πάντα ενεργός πράκτορας ΤΝ μέσα στο κράτος δεν είναι ουδέτερη καινοτομία. Είναι υποδομή ισχύος. Και οι υποδομές ισχύος σε μια δημοκρατία πρέπει να είναι ελέγξιμες και αναστρέψιμες πολιτικά. Αν δεν είναι, τότε το πρόβλημα δεν είναι τεχνολογικό. Είναι βαθιά δημοκρατικό.
Όταν η Τεχνητή Νοημοσύνη παύει να περιμένει εντολές
Για χρόνια, η δημόσια συζήτηση για την Τεχνητή Νοημοσύνη περιστρεφόταν γύρω από έναν ψηφιακό βοηθό που απαντά σε ερωτήσεις, συνοψίζει έγγραφα ή προτείνει κείμενα. Αυτή η εικόνα είναι ήδη ξεπερασμένη. Το πραγματικό διακύβευμα αρχίζει όταν η ΤΝ παύει να περιμένει εντολές και αποκτά μόνιμη παρουσία, πρόσβαση σε εργαλεία, σύνδεση με εξωτερικά γεγονότα και δυνατότητα να δρα ενώ ο άνθρωπος λείπει. Από εκεί και πέρα δεν μιλάμε για ένα απλό λογισμικό παραγωγικότητας. Μιλάμε για μια υποδομή που εισάγει νέο επίπεδο λειτουργικού, θεσμικού και πολιτικού κινδύνου.
Ένας τέτοιος πράκτορας, όταν έχει πρόσβαση σε προσωπικά δεδομένα πολιτών, σε κυβερνητικά πληροφοριακά συστήματα ή σε ευαίσθητες πολιτικές πληροφορίες, δεν είναι απλώς ένα ισχυρό εργαλείο. Είναι ένα νέο σημείο συγκέντρωσης εξουσίας. Κρατά μνήμη, συσχετίζει πληροφορίες από πολλαπλές πηγές, μετατρέπει φυσική γλώσσα σε εντολές, αποκτά ρόλο διαμεσολαβητή ανάμεσα στον δημόσιο λειτουργό και στο σύστημα. Όσο πιο διακριτικά ενσωματώνεται στη ροή εργασίας, τόσο πιο εύκολο είναι να θεωρηθεί φυσιολογικό να του παραχωρούνται όλο και περισσότερα δικαιώματα. Ακριβώς εκεί αρχίζει το πρόβλημα.
Το πρόβλημα δεν είναι μόνο τι ξέρει, αλλά τι μπορεί να κάνει
Η παραδοσιακή ασφάλεια πληροφοριών σχεδιάστηκε γύρω από χρήστες, εφαρμογές και σαφώς οριοθετημένα δικαιώματα. Ο αυτόνομος πράκτορας θολώνει αυτά τα όρια. Δεν βλέπει μόνο πληροφορία, αλλά αποφασίζει πώς θα τη χρησιμοποιήσει. Δεν ανοίγει απλώς ένα αρχείο, αλλά μπορεί να το συσχετίσει με ένα μήνυμα, μια ιστοσελίδα, ένα εσωτερικό υπόμνημα, ένα ημερολόγιο, μια εντολή σε τερματικό ή μια κλήση διεπαφής προγραμματισμού. Αυτό σημαίνει ότι η επιφάνεια επίθεσης μεγαλώνει κατακόρυφα.
Η πιο επικίνδυνη ψευδαίσθηση είναι ότι αρκεί να ορίσουμε δικαιώματα πρόσβασης και το πρόβλημα λύθηκε. Δεν λύθηκε. Ένας πράκτορας που έχει άδεια να διαβάζει, να ταξινομεί, να αναζητά, να πλοηγείται και να ενεργοποιείται από εξωτερικά συμβάντα μπορεί να γίνει αγωγός εξαγωγής δεδομένων, να υποστεί κακόβουλη έγχυση οδηγιών, να παραπλανηθεί από ένα έγγραφο, μια ιστοσελίδα ή ένα ηλεκτρονικό μήνυμα και να μετατρέψει ένα φαινομενικά αθώο ερέθισμα σε αλληλουχία ενεργειών με πραγματικές συνέπειες. Το πρόβλημα, λοιπόν, δεν είναι μόνο η διαρροή. Είναι η μεταφορά πρωτοβουλίας από τον άνθρωπο στο σύστημα.
Σε ένα υπουργείο, σε μια ρυθμιστική αρχή ή σε ένα γραφείο που επεξεργάζεται ευαίσθητες πολιτικές αποφάσεις, αυτός ο κίνδυνος είναι ακόμη πιο σοβαρός. Ο πράκτορας δεν εκτίθεται μόνο σε δεδομένα. Εκτίθεται σε προθέσεις, διαπραγματευτικές θέσεις, σχέδια νόμου, πολιτικά σενάρια, ατελείς εισηγήσεις, εσωτερικές διαφωνίες. Δηλαδή εκτίθεται σε υλικό που αποκτά αξία ακριβώς επειδή δεν είναι δημόσιο. Αν ένα τέτοιο σύστημα είναι κλειστό, μη ελέγξιμο και εξαρτημένο από έναν προμηθευτή, τότε η δημόσια διοίκηση παραχωρεί όχι μόνο λειτουργίες αλλά και γνωσιακή κυριαρχία.
Το μάθημα από τη διαρροή του Claude Code
Η πρόσφατη διαρροή πηγαίου κώδικα του Claude Code έκανε ορατό κάτι που συχνά μένει αόρατο στους χρήστες και στους οργανισμούς: σε κλειστά συστήματα μπορεί να υπάρχουν δυνατότητες, διακόπτες λειτουργιών και επιλογές συμπεριφοράς που το κοινό, οι πελάτες και συχνά ακόμη και οι διαχειριστές δεν γνωρίζουν. Το γεγονός ότι αποκαλύφθηκαν 44 κρυφοί διακόπτες λειτουργιών δεν είναι απλώς τεχνική λεπτομέρεια. Είναι μάθημα διακυβέρνησης. Δείχνει τι σημαίνει να βασίζεσαι σε ένα κρίσιμο ψηφιακό σύστημα χωρίς τη δυνατότητα ουσιαστικού δημόσιου ελέγχου.
Σε ένα έργο ανοιχτού κώδικα, τέτοια στοιχεία δεν θα παρέμεναν αόρατα για πολύ. Αυτό δεν σημαίνει ότι ο ανοιχτός κώδικας είναι μαγική ασπίδα. Σημαίνει κάτι πιο ουσιαστικό και πιο ώριμο: επιτρέπει ανεξάρτητο έλεγχο, επαλήθευση, ανίχνευση ευπαθειών, δημόσια συζήτηση για τον σχεδιασμό και συλλογική βελτίωση. Με άλλα λόγια, μειώνει το πεδίο του άγνωστου. Και στην ασφάλεια, το άγνωστο είναι συχνά πιο επικίνδυνο από το γνωστό ελάττωμα.
Ανοιχτότητα, λογοδοσία και ανθρώπινος έλεγχος
Για το Δημόσιο, η σωστή αρχή δεν είναι να απαγορεύσει την ΤΝ, αλλά να απαγορεύσει την αδιαφανή αυτονομία της ΤΝ σε κρίσιμα πεδία. Κάθε πράκτορας που έχει πρόσβαση σε προσωπικά δεδομένα, διοικητικές πράξεις ή ευαίσθητες πολιτικές πληροφορίες πρέπει να λειτουργεί με ελάχιστα αναγκαία δικαιώματα, πλήρη καταγραφή ενεργειών, υποχρεωτικά σημεία ανθρώπινης έγκρισης και, όπου είναι δυνατόν, με ανοιχτό κώδικα ή τουλάχιστον με πλήρη ελεγκτική δυνατότητα από ανεξάρτητους φορείς.
Ηαρχή πρέπει να είναι απλή. Όσο αυξάνεται η αυτονομία, τόσο πρέπει να αυξάνεται η διαφάνεια. Όσο αυξάνεται η πρόσβαση, τόσο πρέπει να αυξάνεται η λογοδοσία. Όσο πιο κρίσιμο είναι το περιβάλλον χρήσης, τόσο λιγότερο ανεκτό είναι το μαύρο κουτί. Ένας πάντα ενεργός πράκτορας ΤΝ μέσα στο κράτος δεν είναι ουδέτερη καινοτομία. Είναι υποδομή ισχύος. Και οι υποδομές ισχύος σε μια δημοκρατία πρέπει να είναι ελέγξιμες και αναστρέψιμες πολιτικά. Αν δεν είναι, τότε το πρόβλημα δεν είναι τεχνολογικό. Είναι βαθιά δημοκρατικό.
Πηγές
TestingCatalog, “Exclusive: Anthropic tests its own always-on Conway agent”. Χρήσιμο για τα δημόσια ανακατασκευασμένα στοιχεία σχετικά με το Conway, όπως η ξεχωριστή “Conway instance”, τα webhooks, η σύνδεση με Chrome, τα extensions και το μοντέλο συνεχούς ενεργοποίησης: https://www.testingcatalog.com/exclusive-anthropic-tests-its-own-always-on-conway-agent/,
The New Stack, “Inside Claude Code’s leaked source: swarms, daemons, and 44 features Anthropic kept behind flags”. Χρήσιμο για τη δημόσια καταγραφή ότι η διαρροή του Claude Code ανέδειξε 44 feature flags, στοιχείο κομβικό για το επιχείρημα περί αδιαφάνειας σε κλειστά συστήματα: https://thenewstack.io/claude-code-source-leak/,
Στις 10 Μαρτίου 2026, το Ευρωπαϊκό Κοινοβούλιο υιοθέτησε την έκθεση πρωτοβουλίας του Axel Voss για τα πνευματικά δικαιώματα και τη γενετική τεχνητή νοημοσύνη — ένα κείμενο που έχει μεταβληθεί αισθητά σε σχέση με το αρχικό σχέδιο του Ιουνίου.
Μια (επιτέλους) αποδοχή του ισχύοντος νομικού πλαισίου
Η σημαντικότερη αλλαγή σε σχέση με το αρχικό σχέδιο είναι η αναγνώριση ότι η εκπαίδευση συστημάτων ΤΝ καλύπτεται ήδη από τις ισχύουσες εξαιρέσεις για εξόρυξη κειμένων και δεδομένων (Text and Data Mining – TDM). Ενώ το προηγούμενο σχέδιο επιχειρηματολογούσε ότι το Άρθρο 4 της Οδηγίας CDSM δεν εφαρμόζεται στη γενετική ΤΝ, το κείμενο που υιοθετήθηκε τελικά δέχεται την εφαρμογή του υφιστάμενου πλαισίου, ζητώντας «άμεση αποσαφήνιση ως προς την εφαρμογή και την υλοποίησή του». Πρόκειται για σημαντική εξέλιξη, καθώς αποτρέπει τη δημιουργία νομικής αβεβαιότητας για ευρωπαϊκές εταιρείες ΤΝ, ερευνητές και ιδρύματα πολιτιστικής κληρονομιάς.
Παράλληλα, η έκθεση αναγνωρίζει ρητά τον χώρο που το Άρθρο 3 της Οδηγίας CDSM εξασφαλίζει για την ανάπτυξη ΤΝ δημοσίου συμφέροντος. Η Σύσταση 4 καλεί την Επιτροπή να διασφαλίσει ότι δραστηριότητες που διεξάγονται για επιστημονική έρευνα ή εκπαιδευτικούς σκοπούς — ιδίως από ερευνητικούς οργανισμούς και ιδρύματα πολιτιστικής κληρονομιάς — δεν υπόκεινται σε περιορισμούς. Η διάταξη αυτή λειτουργεί ως σαφής εγγύηση: η Βικιπαίδεια, η ανοικτή πρόσβαση σε επιστημονικές εκδόσεις και άλλες κοινόχρηστες πηγές γνώσης δεν πρόκειται να θυσιαστούν στο βωμό εμπορικών συμφερόντων.
Το κεντρικό πρόβλημα: μια αγορά αδειοδότησης που αδυνατεί να λειτουργήσει
Παρά τις θετικές αλλαγές, η έκθεση στηρίζεται σε μια θεμελιώδη παραδοχή που δεν αντέχει στον έλεγχο: ότι μπορούν να αναδυθούν λειτουργικές αγορές αδειοδότησης στο πλαίσιο του ισχύοντος νομικού καθεστώτος. Τίποτα στο υφιστάμενο νομικό πλαίσιο δεν εμποδίζει τους δικαιούχους να διαπραγματεύονται συλλογικά άδειες με προγραμματιστές ΤΝ ήδη σήμερα. Ο λόγος που τέτοιες συμφωνίες δεν έχουν υλοποιηθεί σε ευρεία κλίμακα δεν είναι κάποιο νομικό κενό, αλλά η δομική ανισορροπία στη διαπραγματευτική ισχύ: οι εταιρείες ΤΝ είχαν ελάχιστα κίνητρα να αναζητήσουν άδειες, όταν η εκπαίδευση μοντέλων σε δημόσια διαθέσιμο περιεχόμενο ενέχει περιορισμένο νομικό κίνδυνο.
Το πρόβλημα, δηλαδή, δεν είναι νομικό — είναι οικονομικό και πολιτικό. Η έκθεση επαναλαμβάνει την έκκλησή της για εθελοντική συλλογική αδειοδότηση περίπου τέσσερις φορές σε διαφορετικές συστάσεις, υποδηλώνοντας στην Επιτροπή πού βρίσκεται το κέντρο βάρους της κοινοβουλευτικής θέσης, αφήνοντας ωστόσο εντελώς ανοιχτό τον πραγματικό σχεδιασμό αυτού του μηχανισμού. Το αποτέλεσμα είναι ένα κείμενο που διαγιγνώσκει με σχετική ακρίβεια το πρόβλημα, χωρίς όμως να προτείνει πώς να το αντιμετωπίσει.
Τα μέσα ενημέρωσης και ο κίνδυνος υπερβολικής κανονιστικής ρύθμισης
Το πλέον προβληματικό σημείο της υιοθετημένης έκθεσης εντοπίζεται εκεί όπου πραγματεύεται τα μέσα ενημέρωσης: καλεί την Επιτροπή να διερευνήσει την επέκταση των συγγενικών δικαιωμάτων εκδοτών Τύπου, δημοσιογράφων και ραδιοτηλεοπτικών φορέων ειδήσεων, ώστε να καλύπτουν την εκπαίδευση ΤΝ, την εξαγωγή συμπερασμάτων και τη Retrieval-Augmented Generation, με τέτοιες χρήσεις να απαιτούν «ρητή συναίνεση» και τους δικαιούχους να έχουν «πλήρη έλεγχο» επί του περιεχομένου τους.
Αυτή η διατύπωση είναι ιδιαίτερα ανησυχητική. Τα πνευματικά δικαιώματα δεν αφορούν ποτέ τον «πλήρη έλεγχο» των έργων από τους δικαιούχους· σκοπός τους είναι η δημιουργία ισορροπίας ανάμεσα στα συμφέροντα των δικαιούχων και τα ευρύτερα κοινωνικά συμφέροντα — για την πρόσβαση στη γνώση, την ελευθερία της έκφρασης και την καινοτομία. Η απαίτηση ρητής συναίνεσης για κάθε βήμα πρόσβασης σε πληροφορίες μέσω συστημάτων ΤΝ ισοδυναμεί στην πράξη με αποκλειστικό δικαίωμα — κάτι που έρχεται σε ευθεία αντίθεση με τη δομή των εξαιρέσεων TDM τις οποίες η ίδια η έκθεση πλέον αποδέχεται.
Η πρόταση που η Ευρωπαϊκή Επιτροπή οφείλει να σκεφτεί
Το Open Future προτείνει ένα εναλλακτικό μοντέλο: ένα τέλος (levy) συνδεδεμένο με τα έσοδα από την εμπορική εκμετάλλευση υπηρεσιών ΤΝ, αντί για μεμονωμένες πράξεις αναπαραγωγής κατά τη φάση εκπαίδευσης. Ένα τέτοιο τέλος θα προσέδενε την υποχρέωση στο σημείο όπου η αξία πράγματι υλοποιείται, θα λειτουργούσε βάσει της παραδοχής μαζικής χρήσης που υποστηρίζει την τεκμηρίωση διαφάνειας που η έκθεση προβλέπει, και θα απαλλάσσε τους εμπλεκόμενους από την ανάγκη λεπτομερούς συναλλακτικής διαφάνειας — κάτι που ούτως ή άλλως φαίνεται ανέφικτο στη σημερινή κλίμακα ανάπτυξης συστημάτων ΤΝ.
Το μοντέλο αυτό έχει και ένα επιπλέον πλεονέκτημα: οποιοσδήποτε μηχανισμός αμοιβής αξιώνει να αντιμετωπίσει τη βιωσιμότητα του οικοσυστήματος πληροφοριών πρέπει να φτάνει και σε κοινόχρηστες συνεισφορές, αποθετήρια ανοικτής πρόσβασης, οργανισμούς δημόσιας υπηρεσίας και τους πολλούς μεμονωμένους δημιουργούς των οποίων τα έργα κυκλοφορούν χωρίς εμπορική διαμεσολάβηση.
Η έκθεση του Ευρωπαϊκού Κοινοβουλίου εντοπίζει ορθά το πρόβλημα και ανοίγει έναν πολιτικό διάδρομο για την Ευρωπαϊκή Επιτροπή. Ωστόσο, αυτός ο διάδρομος θα αποδώσει ουσιαστικά αποτελέσματα μόνο εάν η καθυστερημένη ρυθμιστική παρέμβαση ξεπεράσει τη λογική της αδειοδότησης που κυριαρχεί στις συστάσεις της έκθεσης. Ένα σύστημα αδειοδότησης βασισμένο σε ατομικές πράξεις αναπαραγωγής θα ωφελήσει κατά κύριο λόγο τους μεγάλους, καλά οργανωμένους δικαιούχους — αφήνοντας εκτός ακριβώς εκείνους που η έκθεση ισχυρίζεται ότι επιδιώκει να προστατεύσει.
Το Κοινοβούλιο διέγνωσε σωστά την ασθένεια. Πλέον, η Επιτροπή οφείλει να έχει το θάρρος να γράψει τη σωστή συνταγή.
Με αφορμή την Παγκόσμια Ημέρα των Ρομά, στις 8 Απριλίου, η Wikimedia Σερβίας διοργανώνει τον έβδομο παγκόσμιο μαραθώνιο λημματογράφησης. Η πρωτοβουλία αυτή καλεί τους συντάκτες της Βικιπαίδεια να συνεισφέρουν στη δημιουργία και βελτίωση λημμάτων σχετικά με την ιστορία, τον πολιτισμό και τη σύγχρονη ζωή των Ρομά.
Ο στόχος της δράσης είναι η ενίσχυση της ποιότητας και της πληρότητας του περιεχομένου στη Βικιπαίδεια, προσφέροντας τεκμηριωμένες πληροφορίες για θέματα που συχνά υποεκπροσωπούνται. Μέσα από τη συνεργασία της κοινότητας, επιδιώκεται η ανάδειξη πτυχών που παραμένουν λιγότερο ορατές στον ευρύτερο δημόσιο διάλογο.
Η συμμετοχή στην πρωτοβουλία περιλαμβάνει τόσο ενεργή συνεισφορά στη συγγραφή λημμάτων όσο και διάδοση της δράσης, προσελκύοντας νέους συνεισφέροντες και ενισχύοντας την απήχησή της στην κοινότητα.
Ο διαγωνισμός, ο οποίος θα διαρκέσει από τις 7 έως τις 15 Απριλίου, έχει την υποστήριξη του Wikimedia Community User Group Greece, ενώ τα λήμματα είναι δεκτά και ως μέρος του CEE Spring 2026.
Σε μια περίοδο αυξανόμενων γεωπολιτικών εντάσεων και τεχνολογικής ισχύος, η Ευρωπαϊκή Ένωση βρίσκεται μπροστά σε μια κρίσιμη δοκιμασία: θα διατηρήσει την αυτονομία της στην επιβολή των ψηφιακών της νόμων ή θα επιτρέψει εξωτερικές πιέσεις να επηρεάσουν το ρυθμιστικό της πλαίσιο;
Στις αρχές Απριλίου 2026, η Ευρωπαϊκή Επιτροπή ανακοίνωσε την πρόθεσή της να ανοίξει έναν «επίσημο διάλογο» με την κυβέρνηση των Ηνωμένων Πολιτειών σχετικά με την εφαρμογή των ευρωπαϊκών κανόνων για την τεχνολογία. Αν και αυτή η πρωτοβουλία παρουσιάζεται ως μια προσπάθεια ενίσχυσης της διατλαντικής συνεργασίας, οργανώσεις της κοινωνίας των πολιτών, προειδοποιούν ότι ενδέχεται να αποτελέσει επικίνδυνο προηγούμενο.
Οι νόμοι που διακυβεύονται
Το ευρωπαϊκό ψηφιακό οικοδόμημα βασίζεται σε μια σειρά ισχυρών νομοθετημάτων, όπως:
ο Digital Services Act (DSA),
ο Digital Markets Act (DMA),
ο General Data Protection Regulation (GDPR),
και ο AI Act.
Αυτοί οι νόμοι σχεδιάστηκαν για να προστατεύουν τους πολίτες, να διασφαλίζουν τη δημοκρατική λειτουργία του διαδικτύου και να περιορίζουν την υπερβολική ισχύ των μεγάλων τεχνολογικών εταιρειών. Η αποτελεσματικότητά τους, ωστόσο, εξαρτάται άμεσα από την ανεξάρτητη και αυστηρή εφαρμογή τους.
Ο κίνδυνος του «διαλόγου»
Η δημιουργία ενός ειδικού διαύλου επικοινωνίας με τις ΗΠΑ για ζητήματα επιβολής της νομοθεσίας ενδέχεται να λειτουργήσει ως «κερκόπορτα». Μέσω αυτού, κυβερνήσεις και μεγάλες τεχνολογικές εταιρείες θα μπορούσαν να ασκήσουν πολιτική ή οικονομική πίεση με στόχο την αποδυνάμωση των ευρωπαϊκών κανόνων.
Οι ανησυχίες δεν είναι θεωρητικές. Δηλώσεις από την πλευρά των ΗΠΑ δείχνουν σαφή αντίθεση σε ορισμένες ευρωπαϊκές ρυθμίσεις, ενώ έχουν διατυπωθεί ακόμη και απειλές για εμπορικά αντίποινα. Παράλληλα, οι ίδιες οι Big Tech εταιρείες έχουν μακρά ιστορία προσπαθειών καθυστέρησης ή υπονόμευσης κανονισμών μέσω νομικών και πολιτικών παρεμβάσεων.
Ήδη υπάρχουν μηχανισμοί διαβούλευσης
Ένα από τα βασικά επιχειρήματα είναι ότι δεν υπάρχει καμία ανάγκη για έναν νέο, «προνομιακό» διάλογο. Οι ίδιες οι ευρωπαϊκές νομοθεσίες προβλέπουν ήδη διαδικασίες μέσω των οποίων οι εταιρείες μπορούν να εκφράσουν τις θέσεις τους και να συμμετέχουν σε διαβουλεύσεις.
Αντίθετα, το πραγματικό πρόβλημα εντοπίζεται στην έλλειψη διαφάνειας προς το κοινό. Ενώ οι εταιρείες έχουν πρόσβαση σε πολύπλοκους μηχανισμούς επιρροής, οι πολίτες και η κοινωνία των πολιτών συχνά αποκλείονται από ουσιαστική εποπτεία της διαδικασίας επιβολής.
Δημοκρατία, κυριαρχία και εμπιστοσύνη
Η πιθανή θεσμοθέτηση ενός τέτοιου διαλόγου δεν είναι απλώς τεχνικό ζήτημα. Αγγίζει τον πυρήνα της ευρωπαϊκής κυριαρχίας και της δημοκρατικής νομιμοποίησης. Αν η εφαρμογή των νόμων αρχίσει να επηρεάζεται από εξωτερικούς παράγοντες, υπονομεύεται η εμπιστοσύνη των πολιτών στην ικανότητα της Ευρώπης να προστατεύει τα δικαιώματά τους.
Οι οργανώσεις καλούν την Επιτροπή να εγκαταλείψει αυτό το σχέδιο και να επικεντρωθεί σε αυτό που πραγματικά χρειάζεται: ταχύτερη, ισχυρότερη και πιο διαφανή εφαρμογή των υφιστάμενων κανόνων.
Η Ευρώπη έχει επενδύσει σημαντικό πολιτικό κεφάλαιο για να δημιουργήσει ένα από τα πιο προοδευτικά ρυθμιστικά πλαίσια στον κόσμο για την ψηφιακή οικονομία. Το διακύβευμα σήμερα δεν είναι απλώς η συνεργασία με έναν σύμμαχο, αλλά η διατήρηση της ανεξαρτησίας και της αξιοπιστίας αυτού του πλαισίου.
Οι ψηφιακοί νόμοι της Ευρώπης δεν είναι διαπραγματευτικά χαρτιά. Είναι θεμέλια της δημοκρατίας της στην ψηφιακή εποχή.
Την Δευτέρα 30 Μαρτίου, με Ανοιχτή Επιστολή προς την Υπουργό Παιδείας, Θρησκευμάτων και Αθλητισμού, κα Σοφία Ζαχαράκη, 22 φορείς της Κοινωνίας των Πολιτών και ειδικοί, ζήτησαν επίσημη ενημέρωση για τα προγράμματα «AI for Greece» και «Education for Countries» της εταιρείας OpenAI στην Ελλάδα.
Τον Σεπτέμβριο του 2025 το Υπουργείο ανακοίνωσε τη σύναψη μνημονίου συνεργασίας με την OpenAI στο πλαίσιο του προγράμματος «AI for Greece», χωρίς να προηγηθεί ανοικτή και διαφανής διαβούλευση με εκπαιδευτικούς, μαθητές, γονείς και συναφείς οργανώσεις της κοινωνίας των πολιτών.
Μάλιστα, το Υπουργείο σιωπηρώς αρνήθηκε να απαντήσει σε επίσημο αίτημα πρόσβασης σε σχετικά έγγραφα που κατατέθηκε ενώπιον του από τη Homo Digitalis, παρότι αυτό αφορούσε κρίσιμα ζητήματα, όπως η προστασία των προσωπικών δεδομένων μαθητών και εκπαιδευτικών κατά τη χρήση του ChatGPT Edu στα δημόσια σχολεία.
Σύμφωνα με διαθέσιμες πληροφορίες, το πρόγραμμα εφαρμόζεται πιλοτικά σε 20 δημόσιες σχολικές μονάδες δευτεροβάθμιας εκπαίδευσης και εξελίσσεται σε τρία στάδια. Το πρώτο περιλαμβάνει την εκπαίδευση εκπαιδευτικών (Οκτώβριος 2025 – Νοέμβριος 2025), το δεύτερο τη χρήση των εργαλείων ΤΝ από τους ίδιους τους εκπαιδευτικούς (Δεκέμβριος 2025 – Φεβρουάριος 2026) και, τέλος, το τρίτο την εισαγωγή εργαλείων ΤΝ στη μαθησιακή διαδικασία και τη χρήση τους από μαθητές (Μάρτιος – Ιούνιος 2026).
Τις τελευταίες εβδομάδες, η OpenAI βρέθηκε στο επίκεντρο της διεθνούς επικαιρότητας λόγω συνεργασίας με το Υπουργείο Άμυνας των ΗΠΑ, προκαλώντας ερωτήματα για τις πιθανές χρήσεις των τεχνολογιών της εκτός αμερικανικών συνόρων, καθώς δεν υπήρξε σαφής τοποθέτηση για ζητήματα όπως η συλλογή δεδομένων υπηκόων τρίτων χωρών για σκοπούς παρακολούθησης.
Παράλληλα, την ώρα που σε επίπεδο Ευρωπαϊκής Ένωσης εντείνεται η συζήτηση για την ψηφιακή κυριαρχία στην εποχή της τεχνητής νοημοσύνης, με το ευρωπαϊκό πλαίσιο να προκρίνει διαφανείς, ελέγξιμες και ανεξάρτητες λύσεις, η Ελλάδα φαίνεται να κινείται προς την αντίθετη κατεύθυνση. Η επιλογή κλειστών εμπορικών συστημάτων τεχνολογικών εταιριών, όπως η OpenAI, σε ευαίσθητους τομείς, όπως η εκπαίδευση, εντείνει τους προβληματισμούς.
Στην ανοιχτή επιστολή, σκιαγραφείται ένα τοπίο με περισσότερα ερωτήματα παρά απαντήσεις γύρω από την είσοδο της τεχνητής νοημοσύνης στα ελληνικά σχολεία. Ζητείται να αποσαφηνιστεί πώς συνδέονται μεταξύ τους τα δύο προγράμματα της OpenAI στην Ελλάδα, ποια σχολεία συμμετέχουν και με ποια κριτήρια επιλέχθηκαν, αλλά και αν η επιλογή αυτή έγινε με γνώμονα την ισότητα ή κινδυνεύει να διευρύνει υπάρχουσες ανισότητες.
Την ίδια στιγμή, αναδεικνύεται η ανάγκη να γίνει σαφές τι σημαίνει στην πράξη η χρήση του ChatGPT Edu μέσα στην τάξη και αν εξετάστηκαν άλλες, εναλλακτικές και ελέγξιμες λύσεις, βασισμένες στις αρχές του ελεύθερου λογισμικού.
Τέλος, στο επίκεντρο βρίσκεται και το ζήτημα των προσωπικών δεδομένων, καθώς τίθεται στην κα. Υπουργό καίρια ερωτήματα για τα δεδομένα τα οποία συλλέγονται, τους σκοπούς επεξεργασίας τους και τους ιδιώτες που τα διαχειρίζονται.
Μπορείτε να διαβάσετε το κείμενο της επιστολής εδώ.
Ονόματα Φορέων (με αλφαβητική σειρά) Δίκτυο για τα Δικαιώματα του Παιδιού, Ελληνική Ένωση για τα Δικαιώματα του Ανθρώπου (ΕλΕΔΑ), Ελληνικό Φόρουμ Μεταναστών (ΕΦΜ), Ένωση Καταναλωτών για την “Ποιότητα της Ζωής” (ΕΚΠΟΙΖΩ), Ένωση Πληροφορικών Ελλάδας (ΕΠΕ), Ινστιτούτο Έρευνας Ρυθμιστικών Πολιτικών, Οργανισμός Ανοιχτών Τεχνολογιών (ΕΕΛΛΑΚ), ΑΜΚΕ REVMA, Homo Digitalis, Ιn_contACT org, OmniaTV, Open Lab Athens, Reporters United, SolidarityNow, Visible Machines – AI Research and Social Awareness Center, Vouliwatch, WHEN Equity Empowerment Change
Με αφορμή την Παγκόσμια Ημέρα των Ρομά, στις 8 Απριλίου, η Wikimedia Σερβίας διοργανώνει τον έβδομο παγκόσμιο μαραθώνιο λημματογράφησης. Η πρωτοβουλία αυτή καλεί τους συντάκτες της Βικιπαίδεια να συνεισφέρουν στη δημιουργία και βελτίωση λημμάτων σχετικά με την ιστορία, τον πολιτισμό και τη σύγχρονη ζωή των Ρομά.
Ο στόχος της δράσης είναι η ενίσχυση της ποιότητας και της πληρότητας του περιεχομένου στη Βικιπαίδεια, προσφέροντας τεκμηριωμένες πληροφορίες για θέματα που συχνά υποεκπροσωπούνται. Μέσα από τη συνεργασία της κοινότητας, επιδιώκεται η ανάδειξη πτυχών που παραμένουν λιγότερο ορατές στον ευρύτερο δημόσιο διάλογο.
Η συμμετοχή στην πρωτοβουλία περιλαμβάνει τόσο ενεργή συνεισφορά στη συγγραφή λημμάτων όσο και διάδοση της δράσης, προσελκύοντας νέους συνεισφέροντες και ενισχύοντας την απήχησή της στην κοινότητα.
Ο διαγωνισμός, ο οποίος θα διαρκέσει από τις 7 έως τις 15 Απριλίου, έχει την υποστήριξη του Wikimedia Community User Group Greece, ενώ τα λήμματα είναι δεκτά και ως μέρος του CEE Spring 2026.
Η καινοτομία αποτελεί πλέον βασικό πυλώνα για τον εκσυγχρονισμό των δημόσιων διοικήσεων σε ολόκληρη την Ευρώπη και για την αποτελεσματική ανταπόκριση στις ανάγκες των πολιτών. Στο επίκεντρο αυτής της μετάβασης βρίσκεται η πρωτοβουλίαInteroperable Europe, καθώς και η σχετική νομοθεσία που προωθείται από την Ευρωπαϊκή Επιτροπή, με στόχο τη δημιουργία ψηφιακών δημόσιων υπηρεσιών που λειτουργούν απρόσκοπτα πέρα από τα εθνικά σύνορα.
Η σημασία της διαλειτουργικότητας
Η διαλειτουργικότητα — δηλαδή η ικανότητα διαφορετικών συστημάτων και υπηρεσιών να συνεργάζονται αποτελεσματικά — αποτελεί τη βάση για πιο αποδοτικές, προσβάσιμες και φιλικές προς τον χρήστη δημόσιες υπηρεσίες. Μέσω αυτής, τα κράτη μέλη μπορούν να ανταλλάσσουν δεδομένα και να προσφέρουν υπηρεσίες χωρίς εμπόδια, ενισχύοντας την εμπιστοσύνη των πολιτών και των επιχειρήσεων.
Μια δομημένη προσέγγιση στην καινοτομία
Πριν από την εισαγωγή νέων λύσεων, είναι απαραίτητο οι δημόσιες διοικήσεις να αξιολογούν τις υφιστάμενες υπηρεσίες. Οι αξιολογήσεις διαλειτουργικότητας βοηθούν στον εντοπισμό πιθανών προβλημάτων και εξασφαλίζουν ότι τα νέα ψηφιακά συστήματα μπορούν να συνεργαστούν με τα ήδη υπάρχοντα, τόσο σε εθνικό όσο και σε διασυνοριακό επίπεδο.
Πειραματισμός και επαναχρησιμοποίηση
Η καινοτομία ενισχύεται σημαντικά όταν οι οργανισμοί μπορούν να δοκιμάζουν νέες ιδέες και να αξιοποιούν υπάρχουσες λύσεις. Το οικοσύστημα της Διαλειτουργικής Ευρώπης ενθαρρύνει τη χρήση τεχνολογιών αιχμής, όπως η τεχνητή νοημοσύνη, μέσα από ελεγχόμενα περιβάλλοντα δοκιμών (regulatory sandboxes).
Παράλληλα, η πλατφόρμα Interoperable Europe Portal επιτρέπει την ανταλλαγή λύσεων, προτύπων και βέλτιστων πρακτικών, επιταχύνοντας τη διάδοση της καινοτομίας στον δημόσιο τομέα.
Συνεργασία με καινοτόμους φορείς
Η καινοτομία δεν αναπτύσσεται απομονωμένα. Πρωτοβουλίες όπως το GovTech φέρνουν σε επαφή δημόσιες διοικήσεις με νεοφυείς επιχειρήσεις, ερευνητές και παρόχους τεχνολογίας για τη συν-δημιουργία λύσεων.
Ένα χαρακτηριστικό παράδειγμα είναι το πρόγραμμα IMPACTS-EDIC, το οποίο επιτρέπει στα κράτη μέλη να συνεργάζονται για την ανάπτυξη και εφαρμογή ψηφιακών λύσεων σε ευρωπαϊκή κλίμακα, μετατρέποντας πιλοτικές ιδέες σε πραγματικές εφαρμογές.
Ο ρόλος της τεχνητής νοημοσύνης
Η τεχνητή νοημοσύνη χρησιμοποιείται όλο και περισσότερο για τη βελτίωση της αποδοτικότητας και της λήψης αποφάσεων στον δημόσιο τομέα. Στο πλαίσιο της στρατηγικής Apply AI, αναπτύσσεται μια κοινή “εργαλειοθήκη AI” που περιλαμβάνει λύσεις ανοιχτού κώδικα και εργαλεία που μπορούν να επαναχρησιμοποιηθούν.
Επιπλέον, δημιουργείται ένα πλαίσιο καθοδήγησης που βοηθά τις διοικήσεις να υλοποιήσουν υπηρεσίες βασισμένες στην τεχνητή νοημοσύνη με πρακτικά και κατανοητά βήματα.
Ανάδειξη και κλιμάκωση της καινοτομίας
Η πρωτοβουλία Public Sector Tech Watch παρακολουθεί τη χρήση νέων τεχνολογιών στις ευρωπαϊκές διοικήσεις και αναδεικνύει επιτυχημένα παραδείγματα. Μέσω βραβείων και προβολής καλών πρακτικών, ενισχύεται η υιοθέτηση αποδεδειγμένα αποτελεσματικών λύσεων.
Στήριξη των ψηφιακών στόχων της Ευρώπης
Η Διαλειτουργική Ευρώπη συμβάλλει καθοριστικά στη δημιουργία μιας ενιαίας ψηφιακής αγοράς και στην επίτευξη των στόχων της ψηφιακής δεκαετίας, όπως η πλήρης ψηφιοποίηση των δημόσιων υπηρεσιών έως το 2030.
Παράλληλα, υποστηρίζει ευρύτερες ευρωπαϊκές στρατηγικές για την ενίσχυση της ανταγωνιστικότητας και της καινοτομίας, δημιουργώντας ένα πιο συνδεδεμένο και ανθεκτικό δημόσιο τομέα.
Μέσα από τη συνεργασία, τον πειραματισμό και την επαναχρησιμοποίηση λύσεων, η Διαλειτουργική Ευρώπη δημιουργεί τις προϋποθέσεις για έναν πιο σύγχρονο και αποτελεσματικό δημόσιο τομέα. Το αποτέλεσμα είναι υπηρεσίες που λειτουργούν καλύτερα για τους πολίτες, τις επιχειρήσεις και τις ίδιες τις διοικήσεις, ενισχύοντας την ευρωπαϊκή ενοποίηση στην ψηφιακή εποχή.
Οι εκδηλώσεις δεν σταματούν καθώς αυτήν την εβδομάδα πραγματοποιούνται εκδηλώσεις στην Ελλάδα και στο εξωτερικό για τις ανοιχτές τεχνολογίες και την καινοτομία! Ο Οργανισμός Ανοιχτών Τεχνολογιών (ΕΕΛΛΑΚ) σας προτείνει να τις παρακολουθήσετε και να τις διαδώσετε. Μπορείτε επίσης να δείτε περισσότερες εκδηλώσεις για τις επόμενες εβδομάδες ή να καταχωρίσετε τη δική σας εκδήλωση στο: https://ellak.gr/events.
Ο ρόλος του πλέον πυρηνικού κυττάρου της τοπικής αυτοδιοίκησης και γιατί κανείς δεν αλληλεπιδρά μαζί του
Συχνά αναρωτιέμαι, τι μέσα έχουμε στη διεκδίκηση δημόσιου χώρου στην πόλη, πώς να μην αισθανόμαστε ότι δε μας ακούει κανείς; Το ενδιαφέρον μου για τον δημόσιο χώρο δεν υπήρξε ποτέ στεγνά τεχνικό, πηγάζει από μια πεποίθηση ότι ο χώρος που διεκδικούμε και μοιραζόμαστε είναι ταυτόχρονα και εργαστήριο πολιτικής ενεργοποίησης.
Συνεπώς, είχε πολύ ενδιαφέρον για μένα να παρακολουθήσω μέσα από την πλατφόρμα του OpenCouncil, δύο σχετικά ζητήματα να συζητούνται σε ένα ορισμένο πλαίσιο, σαν αυτό της δημοτικής κοινότητας. Συγκεκριμένα, στην δεύτερη δημοτική κοινότητα του Δήμου Αθηναίων έγινε συζήτηση για τη διαμόρφωση ενός κοινόχρηστου χώρου στην Γούβα και για την ανακατασκευή τμημάτων ήπιας κυκλοφορίας στην περιοχή του Μετς, και αν δεν είστε εξοικειωμένοι με την ύπαρξη αυτής της οργανωτικής μονάδας, δεν είστε μόνοι.
Εγγραφείτε!
Τι είναι οι δημοτικές κοινότητες;
Σύμφωνα με το ισχύον θεσμικό πλαίσιο, οι δημοτικές κοινότητες αποτελούν μονάδες εσωτερικής αποκέντρωσης των δήμων. Δεν έχουν νομική προσωπικότητα ούτε διοικητική αυτοτέλεια. Λειτουργούν εντός του ενιαίου νομικού προσώπου του δήμου και τα όργανά τους δεν υποκαθιστούν τα κεντρικά όργανα διοίκησης (Δήμαρχο, Δημοτικό Συμβούλιο, Δημοτική Επιτροπή).
Ωστόσο, διαθέτουν δικά τους αιρετά όργανα, τα οποία εκλέγονται άμεσα από τους πολίτες της οικείας κοινότητας κατά τις δημοτικές εκλογές. Η θητεία τους είναι πενταετής, παράλληλη με εκείνη της δημοτικής αρχής και η αποστολή τους είναι σαφής:
Να εκφράζουν θεσμικά τις ανάγκες της τοπικής κοινωνίας.
Να εισηγούνται και, σε ορισμένες περιπτώσεις, να αποφασίζουν για ζητήματα που αφορούν αποκλειστικά τη γεωγραφική τους ενότητα.
Να λειτουργούν ως δίαυλος επικοινωνίας μεταξύ κατοίκων και δημοτικής αρχής.
Με άλλα λόγια, είναι το πλησιέστερο επίπεδο αυτοδιοίκησης στον πολίτη.
Πότε γίνονται συνεδριάσεις;
Θεωρητικά, οι κοινότητες αυτές αποτελούν το πιο «πυρηνικό» κύτταρο διοίκησης. Θα μπορούσαν να είναι το ιδανικό εργαλείο άμεσης και συμμετοχικής δημοκρατίας, ένας χώρος όπου ο πολίτης καταθέτει άμεσα το πρόβλημα του δρόμου ή της γειτονιάς του χωρίς να χρειάζεται να ανέβει έναν γραφειοκρατικό Γολγοθά, χωρίς να έχει ξοδέψει κοινωνικό κεφάλαιο για να του σηκώσουν το τηλέφωνο.
Το συμβούλιο της δημοτικής κοινότητας συνεδριάζει υποχρεωτικά τουλάχιστον μία φορά τον μήνα.
Απαιτείται απαρτία (παρουσία των ⅔ των μελών).
Οι αποφάσεις λαμβάνονται με απόλυτη πλειοψηφία των παρόντων.
Οι προσκλήσεις δημοσιεύονται τουλάχιστον τρεις ημέρες πριν, στον πίνακα ανακοινώσεων και στην ιστοσελίδα του δήμου.
Οι συνεδριάσεις είναι δημόσιες, επιτρέποντας στους πολίτες να παρακολουθήσουν και να παρέμβουν, σύμφωνα με τον κανονισμό λειτουργίας.
Για παράδειγμα, στη συζήτηση σχετικά με την ανακατασκευή οδών ήπιας κυκλοφορίας στο Μετς (από την οδό Τριβωνιανού ως την οδό Αρχιμήδους), συμμετείχε ο πρόεδρος του συλλόγου Αρδηττός, μιας ενεργής ομάδας πολιτών που ασχολούνται με τα ζητήματα της γειτονιάς τους τακτικά. Στην προκειμένη περίπτωση, εξέφρασαν τον προβληματισμό τους σχετικά με την υλοποίηση του προγράμματος στο σύνολό του ή αν θα μείνει σε μια πιλοτική υλοποίηση που έχει -προφορικά- υποσχεθεί να χρηματοδοτήσει το ίδρυμα Ωνάση (το οποίο φέρεται να έχει στην κατοχή του ορισμένα ακίνητα στους προτεραιοποιημένους δρόμους).
χάρτης από την πλατφόρμα του OpenCouncil για το σημείο συζήτησης
Μάλιστα, μια τέτοια παρέμβαση μπορεί να λάβει χώρα και μέσω της προβλεπόμενης συνέλευσης κατοίκων, την οποία ο πρόεδρος της δημοτικής κοινότητας οφείλει να συγκαλεί τουλάχιστον μία φορά ετησίως, όπου καταγράφονται τα προβλήματα της περιοχής και διατυπώνονται προτάσεις, ενισχύοντας την τοπική διαβούλευση.
Ποιες είναι οι αρμοδιότητες των δημοτικών κοινοτήτων;
Δυστυχώς, η πραγματικότητα απέχει από το όραμα. Σήμερα, οι δημοτικές κοινότητες παραμένουν εγκλωβισμένες και μοιάζουν συχνά διακοσμητικές. Όπως διαπίστωσα, αντί για έναν ζωντανό διάλογο για το μέλλον της γειτονιάς, οι συνεδριάσεις τους συχνά εξαντλούνται σε διεκπεραιωτικά ζητήματα.
Κατά την άποψη μου, αυτό συμβαίνει κυρίως λόγω των αρμοδιοτήτων που έχουν οι δημοτικές κοινότητες, οι οποίες χωρίζονται σε γνωμοδοτικές και αποφασιστικές, με τις πρώτες να αφορούν εισηγήσεις προς τα αρμόδια όργανα του δήμου για κρίσιμα ζητήματα της καθημερινότητας. Συγκεκριμένα, οι κοινότητες μπορούν να εισηγηθούν για τη συντήρηση οδών, πλατειών και παιδικών χαρών, τη βελτίωση του φωτισμού και της καθαριότητας, καθώς και για τη διοργάνωση πολιτιστικών και τοπικών εκδηλώσεων. Παράλληλα, μπορούν να προτείνουν μέτρα για την ενίσχυση της τοπικής κοινωνικής συνοχής και διαμορφώνουν προτάσεις για το τεχνικό πρόγραμμα και τον προϋπολογισμό του δήμου στο μέρος που αναλογεί στην κοινότητά τους. Αλλά, δεν μπορούν να αποφασίσουν για αυτά!
Σε επίπεδο αποφασιστικών αρμοδιοτήτων, οι κοινότητες έχουν το δικαίωμα να λαμβάνουν αποφάσεις για συγκεκριμένα ζητήματα τοπικής εμβέλειας, όπως η διατύπωση γνώμης για τις άδειες χρήσης κοινόχρηστων χώρων ή θέματα που αφορούν καταστήματα υγειονομικού ενδιαφέροντος, όπως η παράταση ωραρίου μουσικής. Οι αποφάσεις αυτές διαβιβάζονται στη συνέχεια στις αρμόδιες υπηρεσίες για τα περαιτέρω.
Τελικά, ο χαρακτήρας των αρμοδιοτήτων ορίζει και το (περιορισμένο) περιεχόμενο των συζητήσεων. Αν κανείς κοιτάξει την ημερήσια διάταξη στις τελευταίες συνεδριάσεις των δημοτικών κοινοτήτων του δήμου Αθηναίων, ο μέγιστος αριθμός των γενικών ζητημάτων ήταν τέσσερα (4), την ώρα που οι περιπτώσεις χορήγησης ή μη παράτασης ωραρίου λειτουργίας σε καταστήματα εστίασης έφταναν από δεκαπέντε (15) έως πενήντα δύο (52)!
Ένας ακόμα λόγος που οι κοινότητες έχουν περιορισμένο ρόλο είναι ότι δεν διαθέτουν αυτοτελή προϋπολογισμό ούτε ανεξάρτητη διοικητική δομή, δηλαδή εξαρτώνται από τις κεντρικές υπηρεσίες του δήμου για την υλοποίηση των αποφάσεών τους.
Για να κατανοήσουμε καλύτερα την αποδυνάμωση των κοινοτήτων στην Ελλάδα τα τελευταία δεκαπέντε χρόνια, είναι χρήσιμο να μελετήσουμε την μετάβαση από την αυτονομία και την διοικητική αποκέντρωση προς τον συγκεντρωτισμό.
1. Εποχή προ-Καλλικράτη (έως το 2010)
Με το σχέδιο «Καποδίστριας», η χώρα διέθετε χιλιάδες μικρούς δήμους και κοινότητες, πολλές από τις οποίες λειτουργούσαν ως αυτόνομες οντότητες με δικό τους προϋπολογισμό.
2. Καλλικράτης (Ν. 3852/2010)
Οι ΟΤΑ μειώθηκαν δραστικά σε 325 μεγάλους δήμους (πλέον 332). Οι πρώην δήμοι και κοινότητες ενσωματώθηκαν σε αυτούς ως δημοτικές ή τοπικές κοινότητες, χάνοντας τη νομική και οικονομική τους αυτοτέλεια.
3. Κλεισθένης Ι (Ν. 4555/2018)
Εισήγαγε χωριστή κάλπη για τις κοινότητες και δυνατότητα ανεξάρτητων συνδυασμών, ενισχύοντας την τοπική εκπροσώπηση και αποσυνδέοντας εν μέρει τη γειτονιά από τα κεντρικά ψηφοδέλτια, κάτι που τελικά ανετράπη στην επόμενη κιόλας εκλογική αναμέτρηση, από τον Ν. 4804/2021.
4. Θεσμικό πλαίσιο 2024 – Εγκύκλιος 94
Η τρέχουσα αυτοδιοικητική περίοδος (1.1.2024–31.12.2028) διαμορφώνει πιο συγκεκριμένη και «σφιχτή» δομή οργάνων:
Σε κοινότητες έως 200 κατοίκους: εκλέγεται Πρόεδρος.
Σε κοινότητες άνω των 200 κατοίκων: εκλέγεται Συμβούλιο Δημοτικής Κοινότητας.
Ο αριθμός των μελών του συμβουλίου καθορίζεται με πληθυσμιακά κριτήρια:
201–2.000 κάτοικοι: 3 μέλη
2.001–10.000 κάτοικοι: 5 μέλη
10.001–50.000 κάτοικοι: 11 μέλη
Άνω των 50.000 κατοίκων: 15 μέλη
Το παράδοξο της εγγύτητας
Αν στην περιφέρεια η επαφή είναι πιο άμεση, με τον ρόλο βέβαια του προέδρου συχνά να περιορίζεται σε αυτόν του διαμεσολαβητή για καθημερινά τεχνικά ζητήματα, σε μεγάλους δήμους, όπως η Αθήνα ή η Θεσσαλονίκη, οι δημοτικές κοινότητες αριθμούν δεκάδες χιλιάδες κατοίκους.
Την ώρα που η κλίμακα αλλοιώνει τον χαρακτήρα της γειτονιάς και οι περιορισμένες αρμοδιότητες αλλοιώνουν την αποφασιστικότητα των κοινοτήτων, οι περισσότεροι από εμάς αγνοούμε την ύπαρξη του ίδιου του οργάνου, ποιος είναι ο πρόεδρος, πού εδρεύει η κοινότητα, πόσο μάλλον κάθε πότε συνεδριάζει. Όλα αυτά, ενώ είναι δεδομένο πως όταν μια γειτονιά εκφράζεται συλλογικά, η πίεση προς τις δημοτικές αρχές αποκτά διαφορετική ισχύ.
Έτσι προκύπτει το παράδοξο της εγγύτητας: Ο θεσμός των δημοτικών κοινοτήτων είναι ο πιο κοντινός στον πολίτη, αλλά παραμένει ο λιγότερο ορατός.
O πλανήτης αποτελεί ένα τόπο συνάντησης των μελών της ελληνικής κοινότητας ΕΛ/ΛΑΚ.
Τα άρθρα του πλανήτη συλλέγονται αυτόματα χωρίς ανθρώπινη παρέμβαση, αποτελούν πνευματική ιδιοκτησία των συγγραφέων τους και αντικατοπτρίζουν τις απόψεις τους.
Η διαχείριση του πλανήτη γίνεται δημόσια μέσα από το σχετικό repository της υπηρεσίας GitHub: greek-libre-planet, όπου μπορείς να ζητήσεις την προσθήκη του blog σου δηλώνοντας το feed της κατηγορίας, του tag, ή το γενικό feed του blog σου, το όνομα/επώνυμο σου και προαιρετικά το avatar σου, αφού πρώτα εγγραφείτε και κατόπιν συνδεθείτε στην υπηρεσία GitΗub, ανοίγοντας νέο issue που θα περιέχει τα συγκεκριμένα στοιχεία σου.
(Αν δεν έχετε λογαριασμό στην υπηρεσία GitHub, για να προστεθει το blog σου θα προστεθεί στον πλανήτη ΕΛ/ΛΑΚ μπορείτε εναλλακτικά να μας αποστειλετε τα παραπάνω στοιχεία στην ηλεκτρονική διεύθυνση info @ eellak gr.)



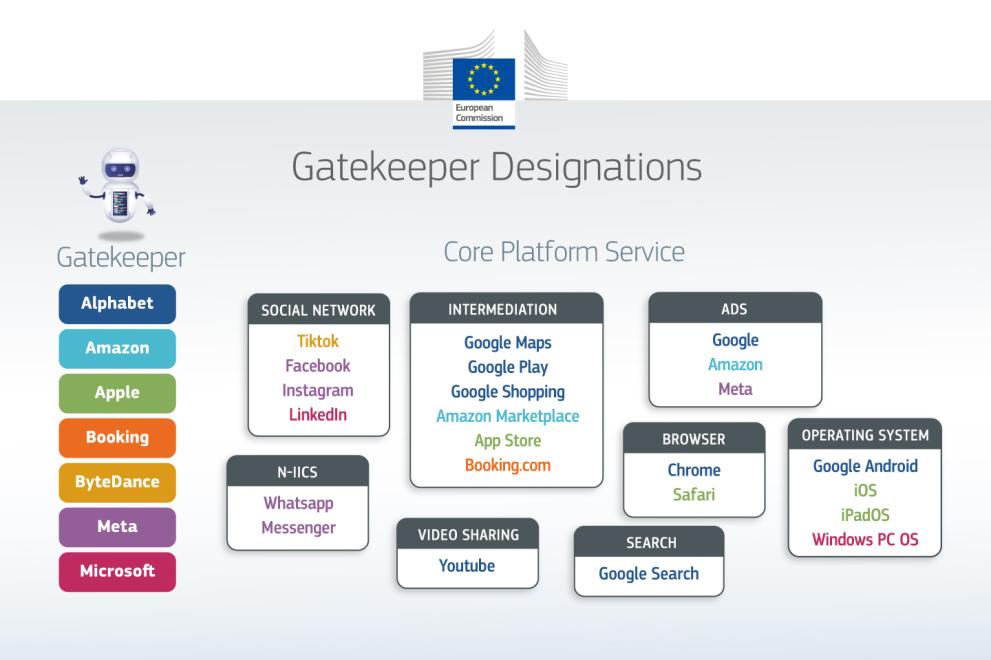









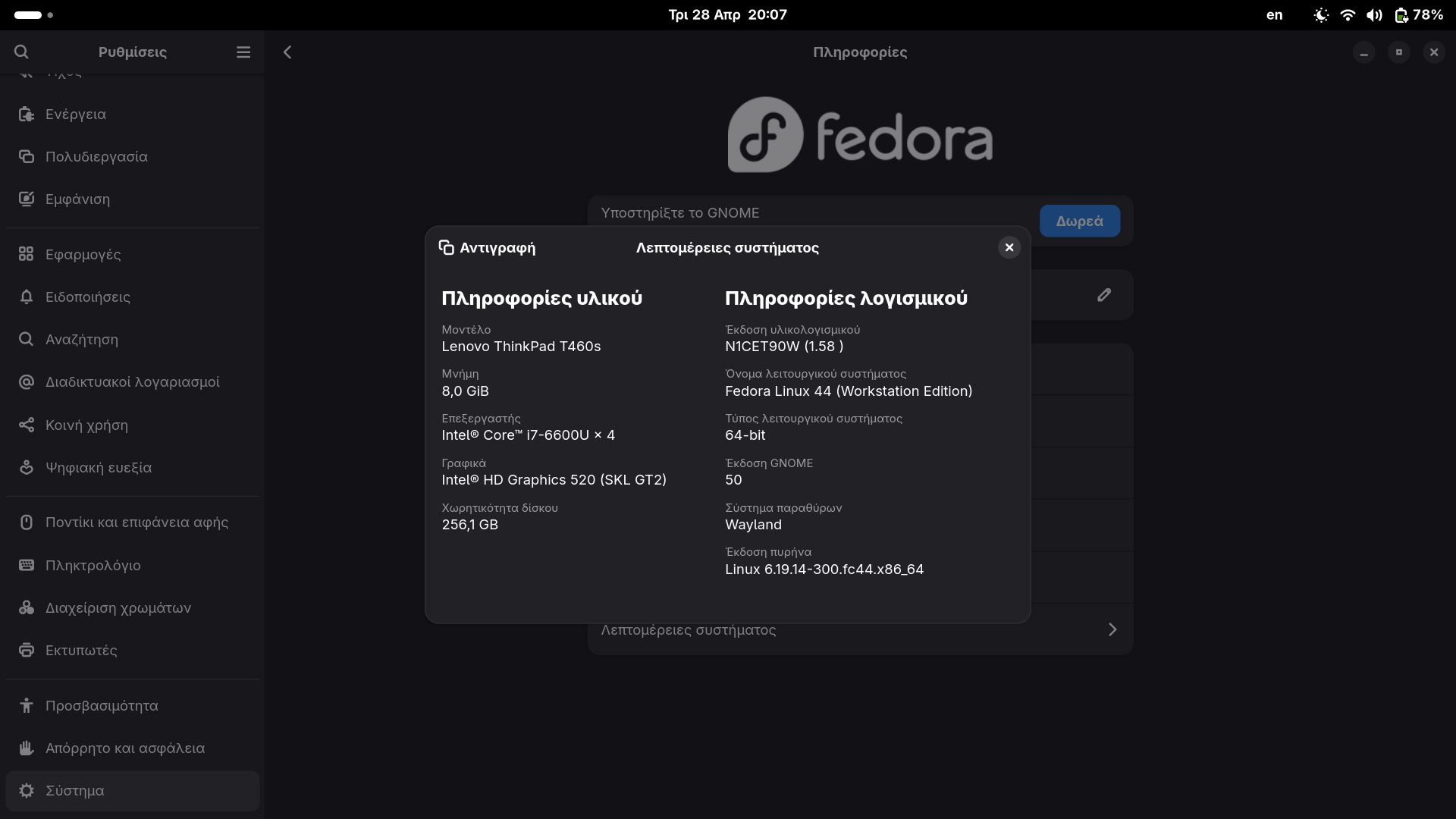



 Κυκλοφόρησε η νέα έκδοση, 44, της διανομής Fedora! Μπορείτε να την
Κυκλοφόρησε η νέα έκδοση, 44, της διανομής Fedora! Μπορείτε να την 

 Πιθανώς ευάλωτα
Πιθανώς ευάλωτα Μη ευάλωτα (εξ ορισμού)
Μη ευάλωτα (εξ ορισμού) Η γκρίζα ζώνη — Συστήματα 64-bit που εκτίθενται
Η γκρίζα ζώνη — Συστήματα 64-bit που εκτίθενται

 Κυκλοφόρησε η νέα έκδοση, 26.04, της διανομής
Κυκλοφόρησε η νέα έκδοση, 26.04, της διανομής